Creating a Lightning-Fast Append-Only Database with mmap in C++

Creating a Lightning-Fast Append-Only Database with mmap in C++
In this code project, I demonstrate the utilization of mmap in C++ to construct a lightning fast append-only database, which I named TurboMap The underlying concept bears resemblance to that of a disk-based hash table, ensuring optimal performance and reliability. A hash table is a data structure that’s accessed by key, which is transformed by a hash function into an index for lookup in a collection of entries.
Append-only databases often exhibit superior performance and scalability characteristics compared to traditional databases that support updates and deletions. Since data is only appended, disk I/O operations can be optimized, reducing contention and enhancing overall throughput.
While the term database may appear ambitious for this implementation, it is essential to acknowledge its limitations. This project does not encompass the comprehensive functionality expected of a full-fledged database, lacking fundamental properties like atomicity. However, its primary objective remains to elucidate foundational concepts to readers, providing a springboard for further development and refinement.
You may be curious about the necessity of the second indirection of index when a straightforward approach, like pointing directly to the appropriate bucket using hash % NUMBER_OF_BUCKETS, seems feasible, as typically done in standard in-memory hash maps. The rationale behind this lies in our lack of precise knowledge regarding the exact location of each bucket within the entry file. This uncertainty arises because we continuously append new entries to the end of the entry file. While one potential solution could involve pre-allocating a large entry file and assigning a predefined segment to each bucket beforehand, such an approach lacks scalability as it imposes constraints on the size of each bucket.
The diagram provided below elucidates the fundamental concept. 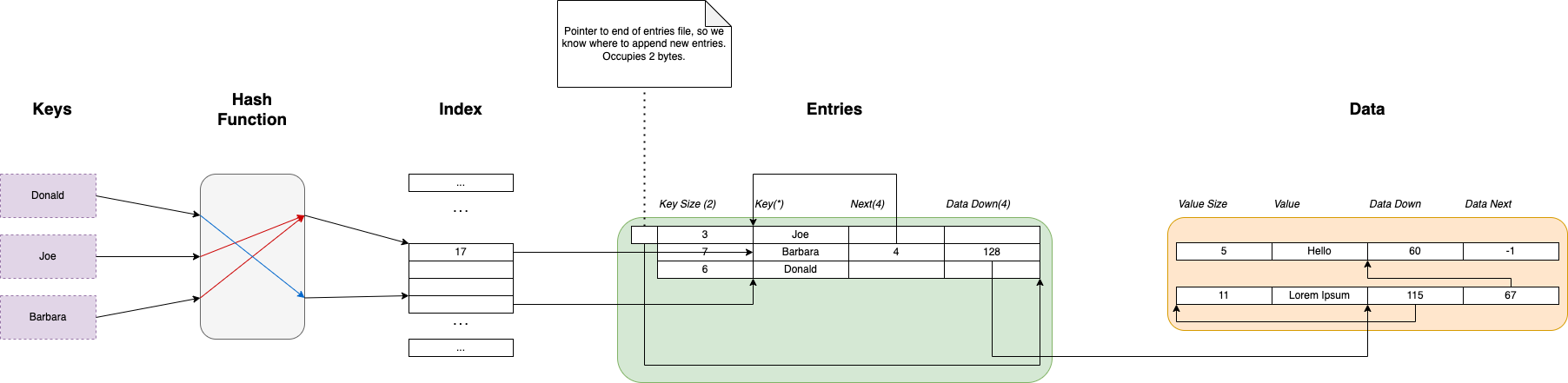
The primary components include:
- A hash function responsible for mapping keys to compact integers (referred to as buckets). An effective hash function ensures that keys are mapped to integers in a manner resembling randomness, facilitating an even distribution of bucket values.
- An index utilized for associating each hash with the most recent entry within its corresponding bucket.
- A file designated for storing map entries. Each entry comprises a key size, the key itself, a reference to the preceding bucket entry, and a pointer to the value record in the data file.
- A data file housing the value records. Each record encompasses the value size, the actual value, a reference to the beginning of the respective record, and a pointer to the previous record associated with the same key.
Our classes interface will be outlined as follows:
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
31
32
33
34
35
36
37
38
39
40
41
42
43
44
45
46
47
48
49
50
51
52
53
54
55
56
57
58
59
60
61
62
63
64
65
66
67
68
69
70
71
72
73
74
75
76
/* TurboMap.h */
#ifndef TURBO_MAP_H
#define TURBO_MAP_H
#include <string>
#define MAX_BUCKETS 100
#define BUCKET_SIZE 1024 * 1024
#define ENTRIES_SIZE (MAX_BUCKETS * BUCKET_SIZE)
#define EMPTY_ENTRY '\0'
class TurboMap {
private:
using INDEX_TYPE = int;
using INDEX_MAP_TYPE = INDEX_TYPE *;
using ENTRIES_TYPE = unsigned char;
using ENTRIES_MAP_TYPE = ENTRIES_TYPE *;
using OFFSET_TYPE = int;
using SIZE_TYPE = uint16_t;
std::string m_data_dir;
std::string m_index_fname;
std::string m_entries_fname;
std::string m_data_fname;
INDEX_MAP_TYPE m_index_map;
ENTRIES_MAP_TYPE m_entries_map;
int m_index_fd;
int m_entries_fd;
int m_data_fd;
size_t m_index_sz;
size_t m_entries_sz;
int m_last_data_pos;
union Entry {
SIZE_TYPE key_size;
char *key;
};
struct Record {
SIZE_TYPE size;
char *value;
};
void Open();
bool DoesFileExist(const std::string &fname);
bool CreateIndexFile(const std::string &fname);
bool CreateEntriesFile(const std::string &fname);
bool CreateDataFile(const std::string &fname);
bool LoadIndexFile(const std::string &fname);
bool LoadEntriesFile(const std::string &fname);
bool LoadDataFile(const std::string &fname);
bool GrowEntriesMap(size_t grow_step);
bool InsertIntoData(std::vector<unsigned char> &serialized_record, size_t sz);
INDEX_TYPE Hash(const std::string &key);
std::string ExtractKeyFromEntryAtKeyOffset(const OFFSET_TYPE &key_off);
OFFSET_TYPE ExtractNextFromEntryAtKeyOffset(const OFFSET_TYPE &key_off);
OFFSET_TYPE ExtractDataDownFromEntryAtKeyOffset(const OFFSET_TYPE &key_off);
SIZE_TYPE GetSizeOfEntryAtKeyOffset(const OFFSET_TYPE &key_off);
OFFSET_TYPE FindEntryForKeyInBucket(const std::string &key, const OFFSET_TYPE &pos);
OFFSET_TYPE LastEntryPositionInBucket(const OFFSET_TYPE &key_off);
SIZE_TYPE FillNewEntry(const std::string &key, const OFFSET_TYPE &next, const OFFSET_TYPE &data_down,
std::vector<ENTRIES_TYPE> &buf);
SIZE_TYPE FillDataRecord(const std::string &value, const OFFSET_TYPE &data_next, std::vector<unsigned char> &buf);
OFFSET_TYPE GetValueFromOffset(std::string &out, OFFSET_TYPE data_offset);
OFFSET_TYPE GetLatestDataOffsetForKey(const std::string &key);
public:
TurboMap(const std::string &dir);
bool InsertKeyValue(const std::string &key, const std::string &value);
bool GetLatestValue(const std::string &key, std::string &out);
void GetAllValues(const std::string &key, std::vector<std::string> &out);
~TurboMap();
};
#endif
This currently represents a rudimentary implementation of a disk-based hash map. Subsequently, I intend to refactor it into a class template to accommodate a wider range of key-value types. For the time being, the utilization of the std::string type should be adequate.
For our hash function, we’ll opt for a straightforward approach for now. However, you can easily swap it out later with a more optimized solution that yields uniformly distributed outputs and faster.
1
2
3
4
5
6
7
TurboMap::INDEX_TYPE TurboMap::Hash(const std::string &key) {
INDEX_TYPE result = 0;
for (size_t i = 0; i < key.length(); ++i) {
result += key[i] * pow(31, i);
}
return result % MAX_BUCKETS;
}
You might have noticed a couple of support private functions. These are designed to assist in file creation and loading from disk.
I will only list the CreateIndexFile(...) function as CreateEntriesFile(...) is similar:
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
31
32
33
34
35
36
37
38
39
bool TurboMap::CreateIndexFile(const std::string &fname) {
m_index_fd = open(fname.c_str(), O_RDWR | O_CREAT | O_TRUNC, (mode_t)0600);
if (m_index_fd == -1) {
perror("Error opening file for writing");
return false;
}
m_index_sz = sizeof(INDEX_TYPE) * MAX_BUCKETS;
// Stretch the file size to m_index_sz
if (lseek(m_index_fd, m_index_sz - 1, SEEK_SET) == -1) {
close(m_index_fd);
perror("Error calling lseek() to 'stretch' the file");
return false;
}
/* Something needs to be written at the end of the file to
* have the file actually have the new size.
* Just writing an empty string at the current file position will do.
*/
if (write(m_index_fd, "", 1) == -1) {
close(m_index_fd);
perror("Error writing last byte of the file");
return false;
}
// Now the file is ready to be mmapped.
m_index_map =
reinterpret_cast<INDEX_MAP_TYPE>(mmap(0, m_index_sz, O_RDWR | O_CREAT | O_TRUNC, MAP_SHARED, m_index_fd, 0));
if (m_index_map == MAP_FAILED) {
err(1, "mmap: %s", fname.c_str());
close(m_index_fd);
return false;
}
return true;
}
We won’t use memory-mapping for the data file. Instead, we’ll load it like this:
1
2
3
4
5
6
7
8
9
bool TurboMap::CreateDataFile(const std::string &fname) {
m_data_fd = open(fname.c_str(), O_RDWR | O_CREAT | O_TRUNC, (mode_t)0600);
if (m_data_fd == -1) {
perror("Error opening file for writing");
return false;
}
m_last_data_pos = 0;
return true;
}
We won’t delve into the file loading process for now; the complete implementation will be provided later. Instead, I’ll elucidate on the primary function of this hash map: the component responsible for inserting and retrieving records.
Inserting Key/Value Pairs
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
31
32
33
34
35
36
37
38
39
40
41
42
43
44
45
46
47
48
49
50
51
52
53
54
55
56
57
58
59
60
61
62
63
64
65
66
bool TurboMap::InsertKeyValue(const std::string &key, const std::string &value) {
// Create a new record
std::vector<unsigned char> new_record;
OFFSET_TYPE data_next = -1;
SIZE_TYPE record_size = FillDataRecord(value, data_next, new_record);
// Pointer to data file
OFFSET_TYPE data_down = m_last_data_pos + record_size - 2 * sizeof(OFFSET_TYPE);
// Get bucket for key
INDEX_TYPE h = Hash(key);
OFFSET_TYPE pos = m_index_map[h]; // Point to key of last bucket entry
OFFSET_TYPE existing_key_entry_offset = -1; // Assume that no entry exists
// Iterate over bucket (linked-list) and find entry with same key, if exists
existing_key_entry_offset = FindEntryForKeyInBucket(key, pos);
// Insert/Update Entry
if (existing_key_entry_offset > 0) { // We already have an entry for key
// Update data next in record to older record data down
data_next = ExtractDataDownFromEntryAtKeyOffset(existing_key_entry_offset);
memcpy(&new_record[record_size - sizeof(OFFSET_TYPE)], &data_next, sizeof(OFFSET_TYPE));
// Update data down pointer to point to new record in data file
SIZE_TYPE key_len = sizeof(ENTRIES_TYPE) * (strlen(key.c_str()) + 1);
memcpy(&m_entries_map[existing_key_entry_offset + key_len + sizeof(OFFSET_TYPE)], &data_down,
sizeof(OFFSET_TYPE));
} else { // We don't have an entry for key. Append a new one to end of bucket
SIZE_TYPE entries_end;
memcpy(&(entries_end), &m_entries_map[0], sizeof(SIZE_TYPE));
// Next points to last bucket entry or -1. This can be a colliding entry for a different key
OFFSET_TYPE next = pos;
// Create a new entry
std::vector<ENTRIES_TYPE> new_entry;
SIZE_TYPE entry_size = FillNewEntry(key, next, data_down, new_entry);
// Insert entry
memcpy(&m_entries_map[entries_end], reinterpret_cast<ENTRIES_MAP_TYPE>(&new_entry[0]), entry_size);
// Point index to latest entry
SIZE_TYPE bucket_pos = entries_end + sizeof(SIZE_TYPE);
memcpy(&m_index_map[h], reinterpret_cast<INDEX_MAP_TYPE>(&bucket_pos), sizeof(SIZE_TYPE));
// Note down new total entries size
entries_end += entry_size;
memcpy(&m_entries_map[0], reinterpret_cast<INDEX_MAP_TYPE>(&entries_end), sizeof(SIZE_TYPE));
// Check if we need to stretch the entry file
if (((entries_end) * 8 + 1024 * 1024) > m_entries_sz && !GrowEntriesMap(10)) {
return false;
}
}
// Insert Data Record
if (InsertIntoData(new_record, record_size)) {
m_last_data_pos += record_size;
return true;
} else {
std::cerr << "Could not persist record" << std::endl;
return false;
}
}
Ok, this is alot of code to digest. So let’s break it down into more manageable parts for easier understanding.
All data that we intend to persist must be casted to unsigned char. To facilitate this, we’ll create a new buffer represented by a std::vector<unsigned char>. This buffer will hold the following data in the specified order:
- The size of the value intended for storage
- The value itself
- A pointer (data down) to the start of this record in the data file
- A pointer (data next) to any preceding record’s data down pointer, or -1 if no such record exists for our key
1
2
3
4
// Create a new record
std::vector<unsigned char> new_record;
OFFSET_TYPE data_next = -1;
SIZE_TYPE record_size = FillDataRecord(value, data_next, new_record);
Following this, we initiate the preparation of our entry element. The initial step involves determining the location to which this entry should point within the data file. This signifies the position of our newly created record that we intend to persist. This pointer will actually reference the data down pointer of our record, hence we subtract two times the size of OFFSET_TYPE.
1
2
// Pointer to data file
OFFSET_TYPE data_down = m_last_data_pos + record_size - 2 * sizeof(OFFSET_TYPE);
Now comes the interesting part. Like any hash function, collisions are inevitable. For each hash, we don’t just store one entry, but rather a linked list (bucket) of entries. When a new insertion is triggered, we must iterate over the corresponding entry list to determine if we already have an entry for that key. If an entry already exists, we simply update it to point to our latest record. Otherwise, we create a new entry and append it to the end of that list.
Initially, we need to ascertain the starting point of the bucket within our entry file:
1
2
3
4
5
6
7
8
// Get bucket for key
INDEX_TYPE h = Hash(key);
OFFSET_TYPE pos = m_index_map[h]; // Point to key of last bucket entry
OFFSET_TYPE existing_key_entry_offset = -1; // Assume that no entry exists
// Iterate over bucket (linked-list) and find entry with same key, if exists
existing_key_entry_offset = FindEntryForKeyInBucket(key, pos);
Let’s put aside the details of the FindEntryForKeyInBucket(...) function for the moment. Essentially, this method traverses the linked list, searching for an entry with the same key. If such an entry exists, it returns the offset of its key in the entry file. Otherwise, it returns -1.
Next, we address the scenario where we already have an existing entry, treating it separately from the case where no such entry exists. Let us focus on the later scenario first.
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
31
32
if (existing_key_entry_offset > 0) { // We already have an entry for key
// Update existing entry
...
} else { // We don't have an entry for key. Append a new one to end of bucket
// 1.
SIZE_TYPE entries_end;
memcpy(&(entries_end), &m_entries_map[0], sizeof(SIZE_TYPE));
// 2.
OFFSET_TYPE next = pos;
// 3.
std::vector<ENTRIES_TYPE> new_entry;
SIZE_TYPE entry_size = FillNewEntry(key, next, data_down, new_entry);
// 4.
memcpy(&m_entries_map[entries_end], reinterpret_cast<ENTRIES_MAP_TYPE>(&new_entry[0]), entry_size);
// 5.
SIZE_TYPE bucket_pos = entries_end + sizeof(SIZE_TYPE);
memcpy(&m_index_map[h], reinterpret_cast<INDEX_MAP_TYPE>(&bucket_pos), sizeof(SIZE_TYPE));
// 6.
entries_end += entry_size;
memcpy(&m_entries_map[0], reinterpret_cast<INDEX_MAP_TYPE>(&entries_end), sizeof(SIZE_TYPE));
// 7.
if (((entries_end) * 8 + 1024 * 1024) > m_entries_sz && !GrowEntriesMap(10)) {
return false;
}
}
To prevent cluttering the code snippet with excessive comments, I’ve extracted the fundamental sections and provided more detailed explanations below:
- The first value in our entries file always represents the total size of all entries contained within the file. This information is crucial because it indicates where we can begin appending our latest entry without overwriting existing data.
- Given that each bucket is represented as a linked list that we traverse in reverse order, we ensure that the next pointer points to the current last entry of the bucket.
- Much like our data record, our new entry will be encapsulated within a
std::vector<unsigned char>, encompassing the key size, the actual key, a pointer to the previous entry (if any), and our data down pointer. - Append the newly created entry at the end of our entries file.
- We update our index file to point to the key offset of our newly persisted entry in the entries file, essentially to the last entry of the bucket.
- We increment the total size holder of all entries contained within the file.
- After mapping a file into memory, we encounter a limitation where its size cannot be increased. To address this, we implement a check to determine if we need to expand our entries file. If expansion is necessary, we unmap it, extend its size by a specified step size, and then remap it into memory.
Let’s consider the scenario where we already have an entry for our key.
1
2
3
4
5
6
7
8
9
10
if (existing_key_entry_offset > 0) { // We already have an entry for key
// 1.
data_next = ExtractDataDownFromEntryAtKeyOffset(existing_key_entry_offset);
memcpy(&new_record[record_size - sizeof(OFFSET_TYPE)], &data_next, sizeof(OFFSET_TYPE));
// 2.
SIZE_TYPE key_len = sizeof(ENTRIES_TYPE) * (strlen(key.c_str()) + 1);
memcpy(&m_entries_map[existing_key_entry_offset + key_len + sizeof(OFFSET_TYPE)], &data_down,
sizeof(OFFSET_TYPE));
}
This is simple:
- We read the data down pointer of the existing record in the data file and update the next pointer of our new record to point to it.
- We update the existing entry to point to the data down pointer of the new record we are about to persist.
Finally, we need to persist our data record as well:
1
2
3
4
5
6
7
if (InsertIntoData(new_record, record_size)) {
m_last_data_pos += record_size;
return true;
} else {
std::cerr << "Could not persist record" << std::endl;
return false;
}
Reading Data
Let us now direct our attention to retrieving values from our hash map.
1
2
3
4
5
6
7
8
bool TurboMap::GetLatestValue(const std::string &key, std::string &out) {
OFFSET_TYPE data_offset = GetLatestDataOffsetForKey(key);
if (data_offset >= 0) {
GetValueFromOffset(out, data_offset);
return true;
}
return false;
}
The function above invokes two additional functions. GetLatestDataOffsetForKey(...) is employed to obtain the offset of the most recent record associated with the specified key in the data file. It leverages the previously introduced function FindEntryForKeyInBucket(...) to locate the entry corresponding to the given key. Subsequently, it extracts and returns the data down pointer from the entry.
The function GetValueFromOffset(...) is dedicated to retrieving the value of the record from the data file situated at the provided offset, subsequently updating the designated output string with the retrieved value. It is responsible for deserializing the record found at the given offset within the data file. Subsequently, it returns the offset to the previous record for the key in the data file, that can be used for iterating down the value chain. If no previous record exists, it returns -1.
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
TurboMap::OFFSET_TYPE TurboMap::GetValueFromOffset(std::string &out, OFFSET_TYPE data_offset) {
// Read data_down
off_t pos = lseek(m_data_fd, data_offset, SEEK_SET);
ssize_t bytes_read;
OFFSET_TYPE buf[1];
bytes_read = pread(m_data_fd, buf, sizeof(OFFSET_TYPE), pos);
OFFSET_TYPE data_down = buf[0];
bytes_read = pread(m_data_fd, buf, sizeof(OFFSET_TYPE), pos + sizeof(OFFSET_TYPE));
OFFSET_TYPE data_next = buf[0];
SIZE_TYPE size[1];
bytes_read = pread(m_data_fd, size, sizeof(SIZE_TYPE), data_down);
SIZE_TYPE value_size = size[0];
// Read value
SIZE_TYPE disk_record_sz = value_size + sizeof(SIZE_TYPE);
std::vector<unsigned char> r(disk_record_sz);
bytes_read = pread(m_data_fd, reinterpret_cast<unsigned char *>(&r[0]), disk_record_sz, data_down);
unsigned char *off = reinterpret_cast<unsigned char *>(&r[0]);
off += sizeof(SIZE_TYPE);
std::string value(off, off + value_size - 1);
out.assign(value);
return data_next;
}
This encompasses the intricate details of our hash map. Let’s now delve into how to utilize it.
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
#include "TurboMap.h"
int main(int argc, char **argv) {
TurboMap map("~/data/");
std::string key = "Joe";
std::string value = "Hello World!";
map.InsertKeyValue(key, value);
std::string latest;
map.GetLatestValue(key, latest);
std::cout << "Latest value for key '" << key << "': " << latest << std::endl;
return 0;
}
Full Implementation
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
31
32
33
34
35
36
37
38
39
40
41
42
43
44
45
46
47
48
49
50
51
52
53
54
55
56
57
58
59
60
61
62
63
64
65
66
67
68
69
70
71
72
73
74
75
76
77
78
79
80
81
82
83
84
85
86
87
88
89
90
91
92
93
94
95
96
97
98
99
100
101
102
103
104
105
106
107
108
109
110
111
112
113
114
115
116
117
118
119
120
121
122
123
124
125
126
127
128
129
130
131
132
133
134
135
136
137
138
139
140
141
142
143
144
145
146
147
148
149
150
151
152
153
154
155
156
157
158
159
160
161
162
163
164
165
166
167
168
169
170
171
172
173
174
175
176
177
178
179
180
181
182
183
184
185
186
187
188
189
190
191
192
193
194
195
196
197
198
199
200
201
202
203
204
205
206
207
208
209
210
211
212
213
214
215
216
217
218
219
220
221
222
223
224
225
226
227
228
229
230
231
232
233
234
235
236
237
238
239
240
241
242
243
244
245
246
247
248
249
250
251
252
253
254
255
256
257
258
259
260
261
262
263
264
265
266
267
268
269
270
271
272
273
274
275
276
277
278
279
280
281
282
283
284
285
286
287
288
289
290
291
292
293
294
295
296
297
298
299
300
301
302
303
304
305
306
307
308
309
310
311
312
313
314
315
316
317
318
319
320
321
322
323
324
325
326
327
328
329
330
331
332
333
334
335
336
337
338
339
340
341
342
343
344
345
346
347
348
349
350
351
352
353
354
355
356
357
358
359
360
361
362
363
364
365
366
367
368
369
370
371
372
373
374
375
376
377
378
379
380
381
382
383
384
385
386
387
388
389
390
391
392
393
394
395
396
397
398
399
400
401
402
403
404
405
406
407
408
409
410
411
412
413
414
415
416
417
418
419
420
421
422
423
424
425
426
427
428
429
430
431
432
433
434
435
436
437
438
439
440
441
442
443
444
445
446
447
448
449
450
451
452
453
454
455
456
457
458
459
460
461
462
463
464
465
466
467
468
469
470
471
472
473
474
475
476
477
478
479
480
481
482
483
484
485
486
487
488
489
490
491
492
493
494
495
496
497
498
499
500
501
502
503
504
505
506
507
508
509
510
511
512
513
514
515
516
517
518
519
520
521
522
523
524
525
526
/* TurboMap.cpp */
#include "TurboMap.h"
#include <err.h> // GNU C lib error messages: err
#include <fcntl.h> // C POSIX libary file control options such as O_RDWR, O_CREAT, O_TRUNC, etc
#include <sys/mman.h> // memory management declarations: mmap, munmap
#include <sys/stat.h> // stat
#include <unistd.h> // C POSIX libary system calls: open, close
#include <iostream> // std::cout
#include <sstream> // std::ostringstream
TurboMap::TurboMap(const std::string &dir)
: m_data_dir(dir),
m_index_fname(m_data_dir + "/index.bin"),
m_entries_fname(m_data_dir + "/entries.bin"),
m_data_fname(m_data_dir + "/data.bin") {
Open();
}
void TurboMap::Open() {
if (!DoesFileExist(m_index_fname)) {
CreateIndexFile(m_index_fname);
} else {
LoadIndexFile(m_index_fname);
}
if (!DoesFileExist(m_entries_fname)) {
CreateEntriesFile(m_entries_fname);
} else {
LoadEntriesFile(m_entries_fname);
}
if (!DoesFileExist(m_data_fname)) {
CreateDataFile(m_data_fname);
} else {
LoadDataFile(m_data_fname);
}
}
/*
A hash function designed to generate an integer hash value for a given string key. The resulting hash is
subsequently employed as an offset in the index file.
*/
TurboMap::INDEX_TYPE TurboMap::Hash(const std::string &key) {
INDEX_TYPE result = 0;
for (size_t i = 0; i < key.length(); ++i) {
result += key[i] * pow(31, i);
}
return result % MAX_BUCKETS;
}
/*
Returns true if file exists. Returns false otherwise.
*/
bool TurboMap::DoesFileExist(const std::string &fname) {
struct stat buffer;
return (stat(fname.c_str(), &buffer) == 0);
}
bool TurboMap::CreateIndexFile(const std::string &fname) {
m_index_fd = open(fname.c_str(), O_RDWR | O_CREAT | O_TRUNC, (mode_t)0600);
if (m_index_fd == -1) {
perror("Error opening file for writing");
return false;
}
m_index_sz = sizeof(INDEX_TYPE) * MAX_BUCKETS;
// Stretch the file size to m_index_sz
if (lseek(m_index_fd, m_index_sz - 1, SEEK_SET) == -1) {
close(m_index_fd);
perror("Error calling lseek() to 'stretch' the file");
return false;
}
/* Something needs to be written at the end of the file to
* have the file actually have the new size.
* Just writing an empty string at the current file position will do.
*
* Note:
* - The current position in the file is at the end of the stretched
* file due to the call to lseek().
* - An empty string is actually a single '\0' character, so a zero-byte
* will be written at the last byte of the file.
*/
if (write(m_index_fd, "", 1) == -1) {
close(m_index_fd);
perror("Error writing last byte of the file");
return false;
}
// // Now the file is ready to be mmapped.
m_index_map =
reinterpret_cast<INDEX_MAP_TYPE>(mmap(0, m_index_sz, O_RDWR | O_CREAT | O_TRUNC, MAP_SHARED, m_index_fd, 0));
if (m_index_map == MAP_FAILED) {
err(1, "mmap: %s", fname.c_str());
close(m_index_fd);
return false;
}
return true;
}
bool TurboMap::CreateEntriesFile(const std::string &fname) {
m_entries_fd = open(fname.c_str(), O_RDWR | O_CREAT | O_TRUNC, (mode_t)0600);
if (m_entries_fd == -1) {
perror("Error opening file for writing");
return false;
}
m_entries_sz = sizeof(ENTRIES_TYPE) * ENTRIES_SIZE;
if (lseek(m_entries_fd, m_entries_sz - 1, SEEK_SET) == -1) {
close(m_entries_fd);
perror("Error calling lseek() to 'stretch' the file");
return false;
}
if (write(m_entries_fd, "", 1) == -1) {
close(m_entries_fd);
perror("Error writing last byte of the file");
return false;
}
m_entries_map = reinterpret_cast<ENTRIES_MAP_TYPE>(
mmap(0, m_entries_sz, O_RDWR | O_CREAT | O_TRUNC, MAP_SHARED, m_entries_fd, 0));
if (m_entries_map == MAP_FAILED) {
err(1, "mmap: %s", fname.c_str());
close(m_entries_fd);
return false;
}
// Set everything to empty
for (int i = 0; i < ENTRIES_SIZE; ++i) {
m_entries_map[i] = EMPTY_ENTRY;
}
// Pointer to where writing can continue
SIZE_TYPE entries_end = sizeof(SIZE_TYPE);
memcpy(&m_entries_map[0], reinterpret_cast<INDEX_MAP_TYPE>(&entries_end), sizeof(SIZE_TYPE));
// Write it now to disk
if (msync(m_entries_map, m_entries_sz, MS_SYNC) == -1) {
perror("Could not sync the file to disk");
return false;
}
return true;
}
bool TurboMap::CreateDataFile(const std::string &fname) {
m_data_fd = open(fname.c_str(), O_RDWR | O_CREAT | O_TRUNC, (mode_t)0600);
if (m_data_fd == -1) {
perror("Error opening file for writing");
return false;
}
m_last_data_pos = 0;
return true;
}
bool TurboMap::LoadIndexFile(const std::string &fname) {
struct stat fs;
m_index_fd = open(fname.c_str(), O_RDWR, (mode_t)0600);
if (m_index_fd == -1) {
err(1, "open mmap: %s", fname.c_str());
return false;
}
if (fstat(m_index_fd, &fs) == -1) {
err(1, "stat:%s", fname.c_str());
return false;
}
m_index_sz = fs.st_size;
m_index_map =
reinterpret_cast<INDEX_MAP_TYPE>(mmap(0, m_index_sz, PROT_READ | PROT_WRITE, MAP_SHARED, m_index_fd, 0));
if (m_index_map == MAP_FAILED) {
err(1, "mmap: %s", fname.c_str());
close(m_index_fd);
return false;
}
return true;
}
bool TurboMap::LoadEntriesFile(const std::string &fname) {
struct stat fs;
m_entries_fd = open(fname.c_str(), O_RDWR, (mode_t)0600);
if (m_entries_fd == -1) {
err(1, "open mmap: %s", fname.c_str());
return false;
}
if (fstat(m_entries_fd, &fs) == -1) {
err(1, "stat:%s", fname.c_str());
return false;
}
/* fs.st_size could have been 0 actually */
m_entries_sz = fs.st_size;
m_entries_map =
reinterpret_cast<ENTRIES_MAP_TYPE>(mmap(0, m_entries_sz, PROT_READ | PROT_WRITE, MAP_SHARED, m_entries_fd, 0));
if (m_entries_map == MAP_FAILED) {
err(1, "mmap: %s", fname.c_str());
close(m_entries_fd);
return false;
}
return true;
}
bool TurboMap::LoadDataFile(const std::string &fname) {
struct stat fs;
m_data_fd = open(fname.c_str(), O_RDWR, (mode_t)0600);
if (m_data_fd == -1) {
err(1, "open mmap: %s", fname.c_str());
return false;
}
if (fstat(m_data_fd, &fs) == -1) {
err(1, "stat:%s", fname.c_str());
return false;
}
m_last_data_pos = lseek(m_data_fd, 0, SEEK_END);
return true;
}
bool TurboMap::GrowEntriesMap(size_t grow_step) {
std::cout << "Grow entries map" << std::endl;
// grow file descriptor with ftruncate(fd, new_size);
// unmap mapped file
// map again with new size
return true;
}
bool TurboMap::InsertIntoData(std::vector<unsigned char> &serialized_record, size_t sz) {
lseek(m_data_fd, 0, SEEK_END);
ssize_t bytes_written = write(m_data_fd, reinterpret_cast<unsigned char *>(&serialized_record[0]), sz);
if (bytes_written == -1) {
close(m_data_fd);
perror("Error writing last byte of the file");
return false;
}
return true;
};
/**
* Returns key from entry at entry_offset
*/
std::string TurboMap::ExtractKeyFromEntryAtKeyOffset(const OFFSET_TYPE &key_off) {
ENTRIES_MAP_TYPE entry_start = &m_entries_map[key_off - sizeof(SIZE_TYPE)];
SIZE_TYPE entry_key_size;
memcpy(&(entry_key_size), entry_start, sizeof(SIZE_TYPE));
std::string key(entry_start + sizeof(SIZE_TYPE), entry_start + sizeof(SIZE_TYPE) + entry_key_size -
1);
return key;
}
/**
* Returns next pointer from entry at entry_offset
*/
TurboMap::OFFSET_TYPE TurboMap::ExtractNextFromEntryAtKeyOffset(const OFFSET_TYPE &key_off) {
ENTRIES_MAP_TYPE entry_start = &m_entries_map[key_off - sizeof(SIZE_TYPE)];
SIZE_TYPE entry_key_len;
memcpy(&entry_key_len, entry_start, sizeof(SIZE_TYPE));
OFFSET_TYPE next;
memcpy(&next, entry_start + sizeof(SIZE_TYPE) + entry_key_len, sizeof(OFFSET_TYPE));
return next;
}
/**
* Returns data down pointer from entry at entry_offset
*/
TurboMap::OFFSET_TYPE TurboMap::ExtractDataDownFromEntryAtKeyOffset(const OFFSET_TYPE &key_off) {
ENTRIES_MAP_TYPE entry_start = &m_entries_map[key_off - sizeof(SIZE_TYPE)];
SIZE_TYPE entry_key_len;
memcpy(&entry_key_len, entry_start, sizeof(SIZE_TYPE));
OFFSET_TYPE data_down;
memcpy(&data_down, entry_start + sizeof(SIZE_TYPE) + entry_key_len + sizeof(OFFSET_TYPE), sizeof(OFFSET_TYPE));
return data_down;
}
/**
* Returns the total size of an entry in bytes
*/
TurboMap::SIZE_TYPE TurboMap::GetSizeOfEntryAtKeyOffset(const OFFSET_TYPE &key_off) {
ENTRIES_MAP_TYPE entry_start = &m_entries_map[key_off - sizeof(SIZE_TYPE)];
SIZE_TYPE entry_key_len;
memcpy(&entry_key_len, entry_start, sizeof(SIZE_TYPE));
return sizeof(SIZE_TYPE) + entry_key_len + sizeof(OFFSET_TYPE) +
sizeof(OFFSET_TYPE); // sizeof(key_len) + key_len + sizeof(next) + sizeof(data_down)
}
/**
* Returns offset of entry that matches the specified key. Return -1 if no such entry exists.
*/
TurboMap::OFFSET_TYPE TurboMap::FindEntryForKeyInBucket(const std::string &key, const OFFSET_TYPE &pos) {
OFFSET_TYPE next = pos;
while (next > 0) {
std::string current_key = ExtractKeyFromEntryAtKeyOffset(next);
if (current_key == key) {
return next;
}
next = ExtractNextFromEntryAtKeyOffset(next);
}
return -1;
};
/**
* Returns offset of last entry at bucket. -1 if no entry exists.
*/
TurboMap::OFFSET_TYPE TurboMap::LastEntryPositionInBucket(const OFFSET_TYPE &key_off) {
ENTRIES_MAP_TYPE entry_start = &m_entries_map[key_off - sizeof(SIZE_TYPE)];
SIZE_TYPE entry_key_size;
memcpy(&(entry_key_size), entry_start, sizeof(SIZE_TYPE));
if (entry_key_size > 0) {
return key_off;
}
return -1;
}
TurboMap::SIZE_TYPE TurboMap::FillNewEntry(const std::string &key, const OFFSET_TYPE &next,
const OFFSET_TYPE &data_down, std::vector<ENTRIES_TYPE> &buf) {
SIZE_TYPE raw_data_size = sizeof(ENTRIES_TYPE) * (strlen(key.c_str()) + 1);
buf.reserve(sizeof(SIZE_TYPE) + raw_data_size);
buf.insert(buf.end(), reinterpret_cast<const unsigned char *>(&raw_data_size),
reinterpret_cast<const unsigned char *>(&raw_data_size) + sizeof(SIZE_TYPE));
const unsigned char *base(reinterpret_cast<const unsigned char *>(key.c_str()));
buf.insert(buf.end(), base, base + raw_data_size);
SIZE_TYPE entry_size = buf.size();
buf.resize(entry_size + sizeof(OFFSET_TYPE));
memcpy(&buf[entry_size], &next, sizeof(OFFSET_TYPE));
entry_size += sizeof(OFFSET_TYPE);
buf.resize(buf.size() + sizeof(OFFSET_TYPE));
memcpy(&buf[entry_size], &data_down, sizeof(OFFSET_TYPE));
entry_size += sizeof(OFFSET_TYPE);
return entry_size;
}
TurboMap::SIZE_TYPE TurboMap::FillDataRecord(const std::string &value, const OFFSET_TYPE &data_next,
std::vector<unsigned char> &buf) {
SIZE_TYPE raw_data_size = sizeof(unsigned char) * (strlen(value.c_str()) + 1);
buf.reserve(sizeof(SIZE_TYPE) + raw_data_size);
buf.insert(buf.end(), reinterpret_cast<const unsigned char *>(&raw_data_size),
reinterpret_cast<const unsigned char *>(&raw_data_size) + sizeof(SIZE_TYPE));
const unsigned char *base(reinterpret_cast<const unsigned char *>(value.c_str()));
buf.insert(buf.end(), base, base + raw_data_size);
SIZE_TYPE record_size = buf.size();
// Data down
OFFSET_TYPE data_down = m_last_data_pos; // points to start of data record
buf.resize(record_size + sizeof(OFFSET_TYPE));
memcpy(&buf[record_size], &data_down, sizeof(OFFSET_TYPE));
record_size += sizeof(OFFSET_TYPE);
buf.resize(buf.size() + sizeof(OFFSET_TYPE));
memcpy(&buf[record_size], &data_next, sizeof(OFFSET_TYPE));
record_size += sizeof(OFFSET_TYPE);
return record_size;
}
bool TurboMap::InsertKeyValue(const std::string &key, const std::string &value) {
// Create a new record
std::vector<unsigned char> new_record;
OFFSET_TYPE data_next = -1;
SIZE_TYPE record_size = FillDataRecord(value, data_next, new_record);
// Pointer to data file
OFFSET_TYPE data_down = m_last_data_pos + record_size - 2 * sizeof(OFFSET_TYPE);
// Get bucket for key
INDEX_TYPE h = Hash(key);
OFFSET_TYPE pos = m_index_map[h]; // Point to key of last bucket entry
OFFSET_TYPE existing_key_entry_offset = -1; // Assume that no entry exists
// Iterate over bucket (linked-list) and find entry with same key, if exists
existing_key_entry_offset = FindEntryForKeyInBucket(key, pos);
// Insert/Update Entry
if (existing_key_entry_offset > 0) { // We already have an entry for key
// Update data next in record to older record data down
data_next = ExtractDataDownFromEntryAtKeyOffset(existing_key_entry_offset);
memcpy(&new_record[record_size - sizeof(OFFSET_TYPE)], &data_next, sizeof(OFFSET_TYPE));
// Update data down pointer to point to new record in data file
SIZE_TYPE key_len = sizeof(ENTRIES_TYPE) * (strlen(key.c_str()) + 1);
memcpy(&m_entries_map[existing_key_entry_offset + key_len + sizeof(OFFSET_TYPE)], &data_down,
sizeof(OFFSET_TYPE));
} else { // We don't have an entry for key. Append a new one to end of bucket
SIZE_TYPE entries_end;
memcpy(&(entries_end), &m_entries_map[0], sizeof(SIZE_TYPE));
// Next points to last bucket entry or -1. This can be a colliding entry for a different key
OFFSET_TYPE next = pos;
// Create a new entry
std::vector<ENTRIES_TYPE> new_entry;
SIZE_TYPE entry_size = FillNewEntry(key, next, data_down, new_entry);
// Insert entry
memcpy(&m_entries_map[entries_end], reinterpret_cast<ENTRIES_MAP_TYPE>(&new_entry[0]), entry_size);
// Point index to latest entry
SIZE_TYPE bucket_pos = entries_end + sizeof(SIZE_TYPE);
memcpy(&m_index_map[h], reinterpret_cast<INDEX_MAP_TYPE>(&bucket_pos), sizeof(SIZE_TYPE));
// Note down new total entries size
entries_end += entry_size;
memcpy(&m_entries_map[0], reinterpret_cast<INDEX_MAP_TYPE>(&entries_end), sizeof(SIZE_TYPE));
// Check if we need to stretch the entry file
if (((entries_end) * 8 + 1024 * 1024) > m_entries_sz && !GrowEntriesMap(10)) {
return false;
}
}
// Insert Data Record
if (InsertIntoData(new_record, record_size)) {
m_last_data_pos += record_size;
return true;
} else {
std::cerr << "Could not persist record" << std::endl;
return false;
}
}
/**
* Fill the out parameter with the value of the record at the given offset. Returns the data file offset to the previous
* record. Returns -1 if no previous record exists.
*/
TurboMap::OFFSET_TYPE TurboMap::GetValueFromOffset(std::string &out, OFFSET_TYPE data_offset) {
// Read data_down
off_t pos = lseek(m_data_fd, data_offset, SEEK_SET);
ssize_t bytes_read;
OFFSET_TYPE buf[1];
bytes_read = pread(m_data_fd, buf, sizeof(OFFSET_TYPE), pos);
OFFSET_TYPE data_down = buf[0];
bytes_read = pread(m_data_fd, buf, sizeof(OFFSET_TYPE), pos + sizeof(OFFSET_TYPE));
OFFSET_TYPE data_next = buf[0];
SIZE_TYPE size[1];
bytes_read = pread(m_data_fd, size, sizeof(SIZE_TYPE), data_down);
SIZE_TYPE value_size = size[0];
// Read value
SIZE_TYPE disk_record_sz = value_size + sizeof(SIZE_TYPE);
std::vector<unsigned char> r(disk_record_sz);
bytes_read = pread(m_data_fd, reinterpret_cast<unsigned char *>(&r[0]), disk_record_sz, data_down);
unsigned char *off = reinterpret_cast<unsigned char *>(&r[0]);
off += sizeof(SIZE_TYPE);
std::string value(off, off + value_size - 1);
out.assign(value);
return data_next;
}
/**
* Returns the data file offset of the latest entry for key. Returns -1 if no entry exists for key.
*/
TurboMap::OFFSET_TYPE TurboMap::GetLatestDataOffsetForKey(const std::string &key) {
// Get bucket for key
INDEX_TYPE h = Hash(key);
OFFSET_TYPE pos = m_index_map[h];
OFFSET_TYPE existing_entry_offset = FindEntryForKeyInBucket(key, pos);
if (existing_entry_offset > 0) {
return ExtractDataDownFromEntryAtKeyOffset(existing_entry_offset);
}
return -1;
}
/**
* Returns data file offset of latest entry if key is present. Fills the out parameter with the value of that latest
* data entry. Returns -1 otherwise.
*/
bool TurboMap::GetLatestValue(const std::string &key, std::string &out) {
OFFSET_TYPE data_offset = GetLatestDataOffsetForKey(key);
if (data_offset >= 0) {
GetValueFromOffset(out, data_offset);
return true;
}
return false;
}
void TurboMap::GetAllValues(const std::string &key, std::vector<std::string> &out) {
std::string existing_value;
OFFSET_TYPE data_down = GetLatestDataOffsetForKey(key);
while (data_down >= 0) {
data_down = GetValueFromOffset(existing_value, data_down);
out.push_back(existing_value);
}
}
TurboMap::~TurboMap() {
if (munmap(m_index_map, m_index_sz) == -1) {
perror("Error un-mmapping the file");
}
if (munmap(m_entries_map, m_entries_sz) == -1) {
perror("Error un-mmapping the file");
}
// /* Un-mmaping doesn't close the file, so we still need to do that.*/
close(m_index_fd);
close(m_entries_fd);
close(m_data_fd);
}
Final Thoughts
I trust you found this post informative. Please feel free to adapt this hash map to suit your project requirements. There are numerous enhancements that can be applied to this code, such as employing templates for more versatile key/value pairs and utilizing lambdas or policies for our hash and equality functions. However, for now, this should provide a solid foundation for understanding the core concepts. Be sure to explore the GitHub repository for this project, where I’ll be actively working on implementing these improvements in the future.