Designing and Implementing a Batch Job Scheduler in C++

Designing and Implementing a Batch Job Scheduler in C++
In this post, I’ll outline how to create a system for scheduling and running batch jobs on data from various sources. Users can easily specify what data sources they want to query and implement business logic on the retrieved data using custom Strategies.
Articulating the process of constructing an entire platform within a handful of blog posts poses a perpetual challenge, particularly when the objective transcends the realm of basic tutorials that merely initiate users into the rudiments of utilizing a third-party framework. While such tutorials undoubtedly serve a purpose, especially for novices acquainting themselves with a new skill or technology, their scope tends to be rather constrained, often culminating in the creation of elementary TODO list web applications. The acquisition of more comprehensive skills of this nature typically occurs through hands-on experience in professional settings, which may pose difficulties for those just embarking on their journey. Alternatively, delving into white papers can provide a deeper understanding of the subject matter, offering insights that surpass the surface-level explanations found in introductory tutorials. Without further ado, let’s dive in and get started!
I utilize this solution within my automated stock trading platform, leveraging the TWS API as the primary data source. As the system is quite intricate for a blog post, I’ll mainly focus on giving an overview of the platform and its core components. I’ll include code snippets where needed to explain concepts clearly or to showcase elegant coding techniques that readers can learn from. The entire platform is built in C++, which is supported by the TWS API and happens to be my preferred programming language.
For further implementation details, you can explore a more generic version of this platform available on my GitHub account. Feel free to utilize it as a foundational framework for your own project, incorporating any necessary requirements as needed.
Main Components
At the foundation of the platform lie the following components:
TWSClientis my custom client that connects to the TWS/Gateway data source and requests market data.TWSCallbackis an implementation of the EWrapper Interface used by the TWS/Gateway to communicate with our application. Every TWS API consumer application needs to implement this interface in order to handle all the events/data generated by the TWS/Gateway. Data received from the TWS/Gateway (or any other data source) is then made available to theDispatcher, which distributes it to any subscribed strategies.AbstractStrategyis an abstraction that concrete strategies need to implement to handle the fetched data and run business logic. A strategy subscribes to the dispatcher for any data that it requires.Dispatcherreceives data from the data source and pushes it to any subscribed strategies so that they can perform their business logic.Schedulerholds an internal timer and notifies the strategies that they should execute their logic when the required interval has elapsed.Platformreads any configurations, initializes the dispatcher and scheduler, registers the strategies with the scheduler, and connects the different components together.
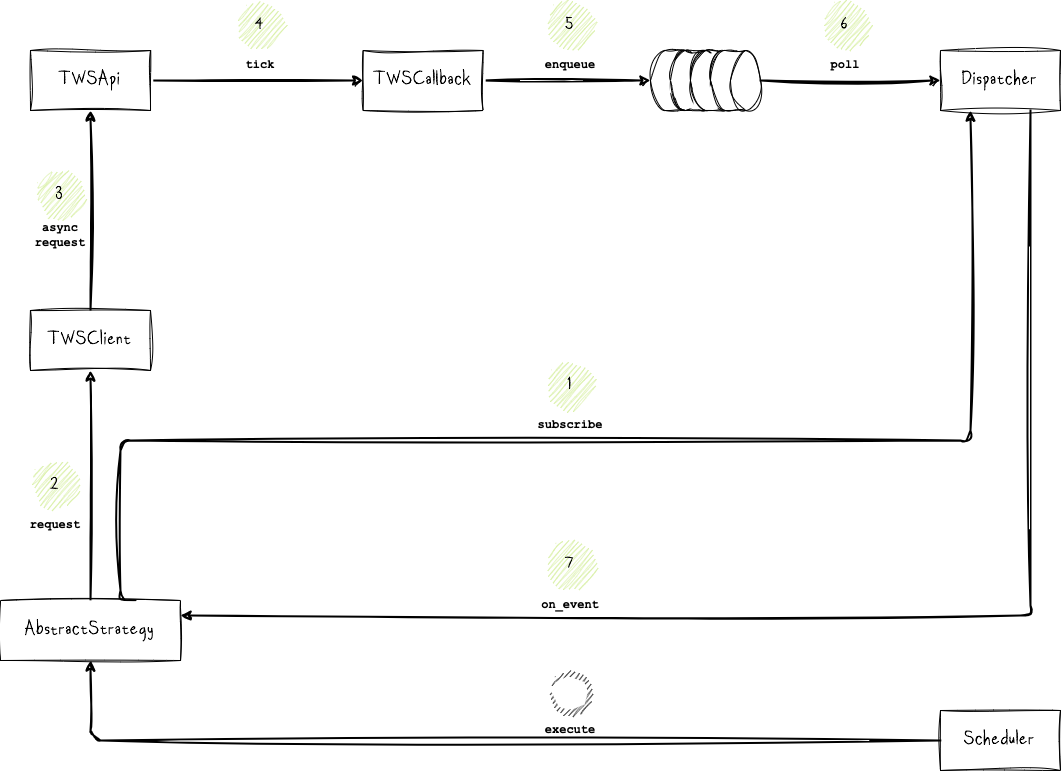
As TWSClient and TWSCallback are predominantly tailored to my particular requirements and data source, I will refrain from delving into extensive details within this post. However, I may consider dedicating a separate article to elucidate these components in the future. For the present, suffice it to say that they function as clients to an API, facilitating data retrieval through queries.
AbstractStrategy
Concrete strategies will be required to implement this interface. These strategies will provide appropriate implementations tailored to specific business requirements.
I won’t delve into the specifics of every function in AbstractStrategy to keep the focus on the main concepts. However, I’ll make the source code available on GitHub so you can review it later if needed.
Thinking from the perspective of a platform user, the implementation and deployment of a new strategy should be as straightforward as possible. Ideally, the strategy implementer should not need to modify platform code, except for creating their concrete implementation of the strategy interface. With this in mind, I have distilled the basic requirements down to the following:
- A strategy should have the capability to subscribe to events that may occur in the future, such as price increments (ticks) of specific securities. These events are categorized as asynchronous requests, meaning we inform the platform about what we want and receive notifications along with the accompanying data when these events occur at some point in the future.
- A strategy should possess the capability to request current data, such as current price for a given ticker symbol, and remain in a blocked state until it receives a response. These events are categorized as synchronous or blocking requests.
- A strategy should be able to handle new incoming events.
- A strategy should be capable of maintaining an internal state. This is particularly crucial if execution should be postponed until all necessary data has been collected for the algorithm.
- The scheduler must have the capability to notify the strategy when it is time to execute.
- Entry and exit points for initializing the strategy before execution and cleaning up afterward should also be available to the strategy developer.
- A method for registering and unregistering strategies with the scheduler must be provided.
Below is a simplified interface for AbstractStrategy, devoid of any extraneous clutter (forward and friend declarations, etc.) or supporting code that might distract from the core concepts:
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
31
32
33
34
/* AbstractStrategy.h */
class AbstractStrategy
{
private:
virtual bool init() = 0;
virtual void execute() = 0;
virtual void clean() = 0;
void activate();
void process();
void request_ticks();
std::shared_ptr<TWSClient> m_client; // Client for data source
std::map<std::string, std::unordered_set<Subscription, Subscription::Hash, Subscription::Eq>> m_subscriptions;
SafeQueue<API::CallbackEvent> m_event_queue;
SignalChannel *m_scheduler_sig_channel;
std::atomic<bool> m_should_run;
protected:
void schedule(const long interval);
// Async calls
void subscribe_to_tick_events(RequestID &req_id, const std::string &symbol, const std::string &sec_type, const std::string ¤cy, const std::string &exchange);
// Blocking calls
const API::CallbackEvent request_price_sync(const std::string &symbol, const std::string &sec_type, const std::string ¤cy, const std::string &exchange);
public:
AbstractStrategy(std::string name, std::shared_ptr<TWSClient> client);
virtual void on_event(const API::CallbackEvent &msg) = 0;
~AbstractStrategy(){};
};
init()
This method must be overridden by any concrete strategies. Typically, the strategy may make any synchronous requests, subscribe to events with the dispatcher, and schedule an execution interval with the scheduler.
1
2
3
4
5
6
7
8
bool ConcreteStrategy::init()
{
...
RequestID req_id_ticker = -1;
subscribe_to_tick_events(req_id_ticker, "IBM", "STK", "USD", "SMART");
schedule(5000);
return true;
}
execute()
This method must be overridden by any concrete strategies. It encapsulates the actual business logic of the strategy and is called when the scheduler notifies the strategy that it’s time for execution.
activate()
When the scheduler starts, it initially callsactivate()on all registered strategies. The strategy then runs theprocess()function in a new thread.
process()
This is where the strategy’s main loop is implemented. Typically, it waits on a condition variable and is awakened when the scheduler notifies it that it’s time to execute.
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
31
32
33
34
35
36
37
38
39
40
41
42
43
44
45
46
47
48
49
50
void AbstractStrategy::process()
{
m_should_run.store(init());
if (!m_should_run.load())
{
// Not scheduled. Just exit.
return;
}
request_ticks();
while (m_should_run.load())
{
{
std::unique_lock schedule_lock(m_scheduler_sig_channel->m_cv_mutex);
// Wait with timeout to occasionally wake up and check should_run signal
m_scheduler_sig_channel->m_cv.wait_for(
schedule_lock,
std::chrono::milliseconds(1000),
[this]()
{
bool should_stop = m_scheduler_sig_channel->m_exit_wait.load();
return should_stop;
});
if (m_scheduler_sig_channel->m_exit_wait.load())
{
// We were woken up because there is actually data available and not because of timeout
m_scheduler_sig_channel->m_exit_wait.store(false);
schedule_lock.unlock();
{
std::unique_lock lock(*m_log_cv_mutex);
}
execute(); // Template method pattern. Implemented by derived classes.
{
std::unique_lock lock(*m_log_cv_mutex);
}
}
}
std::this_thread::sleep_for(std::chrono::milliseconds(10));
}
// Exit main loop. Clean up.
clean(); // Template method pattern. Implemented by derived classes.
}
request_ticks()
Gets called before the strategy enters its main loop. It iterates over its subscriptions and informs the data source client that we want to receive notifications and data about specific types. Additionally, a strategy must subscribe with the dispatcher, as it is the entity responsible for receiving responses from the data source callback and forwarding them to the requesting strategy.
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
void AbstractStrategy::request_ticks()
{
for (const auto &[key, subscriptions] : m_subscriptions)
{
for (auto &sub : subscriptions)
{
std::stringstream ss;
if (sub.type == API::EventType::TICK_PRICE)
{
*sub.req_id = m_client->request_price(sub.symbol, sub.sec_type, sub.currency, sub.exchange);
std::cout << "Requesting ticks for: " << sub.to_string() << std::endl;
}
}
}
}
schedule()
Informs the scheduler about the strategy and schedules the strategy to be executed at the specified interval.
1
2
3
4
void AbstractStrategy::schedule(const long interval)
{
m_scheduler_sig_channel = Scheduler::instance().schedule_strategy(this, interval);
}
subscribe_to_tick_events()
Subscribe to specific events with the dispatcher.
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
void AbstractStrategy::subscribe_to_tick_events(RequestID &req_id, const std::string &symbol, const std::string &sec_type, const std::string ¤cy, const std::string &exchange)
{
Subscription sub;
sub.req_id = &req_id;
sub.type = API::EventType::TICK_PRICE;
sub.symbol = symbol;
sub.sec_type = sec_type;
sub.exchange = exchange;
sub.currency = currency;
std::string key = subscription_key(API::EventType::TICK_PRICE, sub);
if (m_subscriptions.find(key) == m_subscriptions.end())
{
m_subscriptions.insert(std::make_pair(key, std::unordered_set<Subscription, Subscription::Hash, Subscription::Eq>()));
Dispatcher::instance().add_listener(std::bind(&AbstractStrategy::on_event, this, std::placeholders::_1), key);
}
m_subscriptions[key].emplace(sub);
}
on_event(msg)
Called by the dispatcher to notify the strategy about any new events that the strategy has subscribed to. The strategy can then utilize this new information to update its internal state and prepare for execution when the time comes.
clean()
Gets called when the strategy exits its main loop for whatever reason. This provides the strategy with the opportunity to close any open files, databases, and perform any necessary cleanups before exiting.
Dispatcher
The dispatcher, as its name implies, is responsible for routing incoming data to the strategies that have requested it. There exists only one instance of the dispatcher, which continuously polls the event queue for incoming events originating from the data source. When new events are made available by the data source, the dispatcher notifies all subscribers of the event. This process is facilitated by executing the AbstractStrategy::on_event(...) method within the strategy class in a separate thread. This allows the dispatcher to proceed with notifying the remaining subscribers without waiting for the completion of on_event(...) for each subscriber.
Below is a simplified interface for Dispatcher. Once more, any supporting code has been omitted for clarity reasons.
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
/* Dispatcher.h */
class Dispatcher
{
public:
using Listener = std::function<void(const API::CallbackEvent &)>;
private:
Dispatcher();
void run();
void notify_async(Listener callback, const API::CallbackEvent msg);
std::map<std::string, std::list<Listener>> m_targets_map;
public:
Dispatcher(const Dispatcher &) = delete;
Dispatcher &operator=(const Dispatcher &) = delete;
void start();
ListenerCookie add_listener(Listener &&r, std::string key);
void notify_all(const API::CallbackEvent &);
static Dispatcher &instance();
~Dispatcher();
std::shared_ptr<SafeQueue<API::CallbackEvent>> m_queue;
};
#endif
Let’s review the main methods.
start()
Initiates the main loop of the dispatcher within a distinct thread.
run()
This is where the dispatcher’s main loop is implemented. Typically, the dispatcher will poll the event queue for new events and then notify any subscribers if new events are available.
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
void Dispatcher::run()
{
m_should_run = true;
while (!m_sig_channel->m_exit_wait.load() && m_should_run)
{
{
std::unique_lock shutdown_lock(m_sig_channel->m_cv_mutex);
m_sig_channel->m_cv.wait_for(shutdown_lock, std::chrono::milliseconds(10), [this]()
{ bool should_shutdown = m_sig_channel->m_exit_wait.load();
return should_shutdown; });
}
API::CallbackEvent event;
m_queue->dequeue_with_timeout(1000, event);
if (event.type != API::EventType::EMPTY)
{
notify_all(event);
}
std::this_thread::sleep_for(std::chrono::milliseconds(10));
}
}
add_listener(listnere, event_key)
Called by a strategy to subscribe to a new event with the dispatcher. An event is uniquely identified by an event key, which is known to both the strategy and the dispatcher.
1
2
3
4
5
6
7
8
9
10
11
Dispatcher::ListenerCookie Dispatcher::add_listener(Listener &&r, std::string key)
{
auto l = lock();
auto it = m_targets_map.find(key);
if (it == m_targets_map.end())
{
m_targets_map.insert(std::make_pair(key, std::list<Listener>()));
}
return m_targets_map[key].emplace(m_targets_map[key].cend(), std::move(r));
}
notify_all(msg)
Notifies all listeners that have subscribed to the incoming event.
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
void Dispatcher::notify_all(const API::CallbackEvent &msg)
{
auto l = lock();
std::string key = event_key(msg); // Get key for the event
if (m_targets_map.find(key) != m_targets_map.end())
{
auto listeners = m_targets_map[key];
for (auto it = listeners.cbegin(); it != listeners.cend(); ++it)
{
notify_async(*it, msg);
}
}
else
{
std::cout << "No subscribers for event: " + msg.to_string() << std::endl;
}
}
notify_async(callback, msg)
Invokes the subscriber’s callback in a detached thread, ensuring that we don’t have to wait before notifying other listeners.
1
2
3
4
void Dispatcher::notify_async(Listener callback, const API::CallbackEvent msg)
{
std::thread([callback, msg]{ callback(msg); }).detach();
}
instance()
A straightforward implementation of the singleton design pattern to provide a single instance of the dispatcher.
1
2
3
4
5
Dispatcher &Dispatcher::instance()
{
static Dispatcher i;
return i;
}
Scheduler
The scheduler is a crucial component of the entire platform. Its primary responsibility is to manage execution intervals and ensure that our strategies are executed within their configured intervals. Once more, let’s begin by defining our simplified interface.
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
/* Scheduler.h */
class Scheduler
{
private:
Scheduler();
SignalChannel *schedule_strategy(AbstractStrategy *strategy, long time);
void run();
std::map<std::string, long> m_interval_registry; // Strategy name -> milliseconds
std::map<std::string, std::chrono::system_clock::time_point> m_time_last_run_registry; // Strategy name -> time
std::map<std::string, SignalChannel *> m_notifications_registry; // Strategy name -> cv
std::unordered_set<AbstractStrategy *, AbstractStrategy::Hash, AbstractStrategy::Eq> m_strategies;
public:
Scheduler(const Scheduler &) = delete;
Scheduler &operator=(const Scheduler &) = delete;
static Scheduler &instance();
void register_strategy(AbstractStrategy *strategy);
void start();
~Scheduler();
std::shared_ptr<SignalChannel> m_sig_channel;
std::atomic<size_t> *m_running_strategies;
std::condition_variable *m_log_cv;
std::mutex *m_log_cv_mutex;
bool m_should_run;
};
Let’s examine what some of the methods accomplish behind the scenes.
start()
Initiates the main loop of the scheduler within a distinct thread.
run()
This is where the scheduler’s main loop is implemented. Typically, the scheduler checks when each strategy was last run. If enough time has elapsed since the last run, the scheduler notifies the strategy that it can execute. This is achieved using condition variables, on which each strategy waits. Before entering the main loop, the scheduler also ensures that each strategy is activated.
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
31
32
33
34
35
36
37
38
39
40
41
42
43
44
45
void Scheduler::run()
{
m_should_run = true;
for (auto s : m_strategies)
{
s->m_should_run.store(true);
s->activate();
}
while (!m_sig_channel->m_exit_wait.load() && m_should_run)
{
{
std::unique_lock shutdown_lock(m_sig_channel->m_cv_mutex);
m_sig_channel->m_cv.wait_for(shutdown_lock, std::chrono::milliseconds(10), [this]()
{ bool should_shutdown = m_sig_channel->m_exit_wait.load();
return should_shutdown; });
}
// Check if any strategies should run
auto now = std::chrono::system_clock::now();
for (const auto &[strategy_name, last_time] : m_time_last_run_registry)
{
long interval = m_interval_registry[strategy_name];
double elapsed_time = std::chrono::duration<double, std::milli>(now - last_time).count();
if (elapsed_time >= interval)
{
SignalChannel *sig = m_notifications_registry[strategy_name];
{
std::unique_lock lock(sig->m_cv_mutex);
sig->m_exit_wait.store(true);
}
m_time_last_run_registry[strategy_name] = now;
sig->m_cv.notify_one();
}
}
}
std::cout << "Shutting down" << std::endl;
for (auto s : m_strategies)
{
s->m_should_run.store(false);
s->join();
}
}
register_strategy()
This method facilitates the registration of strategies with the scheduler, ensuring that only registered strategies are considered for execution.
1
2
3
4
5
6
7
void Scheduler::register_strategy(strategy)
{
m_strategies.insert(strategy);
strategy->m_running_strategies = m_running_strategies;
strategy->m_log_cv = m_log_cv;
strategy->m_log_cv_mutex = m_log_cv_mutex;
}
schedule_strategy(strategy, time)
Typically invoked by a concrete strategy during initialization, this method allows a strategy to inform the scheduler of its desire to execute at specified time intervals, measured in milliseconds. The scheduler provides acondition_variable(encapsulated within aSignalChannelobject) on which the strategy can await notification of the designated execution time.
1
2
3
4
5
6
7
8
9
10
SignalChannel *Scheduler::schedule_strategy(AbstractStrategy *strategy, long time)
{
m_interval_registry[strategy->m_name] = time;
m_time_last_run_registry[strategy->m_name] = std::chrono::system_clock::now();
if (m_notifications_registry.find(strategy->m_name) == m_notifications_registry.end())
{
m_notifications_registry[strategy->m_name] = new SignalChannel();
}
return m_notifications_registry[strategy->m_name];
}
instance()
A straightforward implementation of the singleton design pattern to provide a single instance of the Scheduler.
1
2
3
4
5
Scheduler &Scheduler::instance()
{
static Scheduler i;
return i;
}
Indeed, we’ve covered a lot of ground, outlining the main components of our system. Now, it’s time to integrate and orchestrate them, bringing all the pieces together to start running our strategies. This is where the final piece of the puzzle, the Platform component, comes into play.
Platform
Before any strategy execution can commence, we must initialize and start several components, some of which run in separate threads. This includes listening for interrupt signals for potential application exits, registering any strategies, and establishing connections to our data sources. Additionally, we need to set up additional supporting parts such as logging, which have not been detailed in this post. Once more, let’s begin by defining our fundamental interface.
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
/* Platform.h */
class Platform
{
private:
std::shared_ptr<SafeQueue<API::CallbackEvent>> init_dispatcher(std::shared_ptr<SignalChannel> sig_channel);
void init_scheduler(std::shared_ptr<SignalChannel> sig_channel);
void process_loop();
bool try_connect(std::shared_ptr<SafeQueue<API::CallbackEvent>> callback_event_queue, std::shared_ptr<SignalChannel> sig_channel);
TWSCallback *m_tws_callback;
std::shared_ptr<TWSClient> m_client;
public:
Platform(const std::string &host, const int port, const char *connect_options);
void on_connect(const API::CallbackEvent &msg);
bool start();
~Platform();
};
init_dispatcher(…)
As the name implies, this method initializes the dispatcher and returns a queue that will be shared with both our data sources and the dispatcher. The data sources can utilize this queue to publish any new events, which the dispatcher can then poll.
1
2
3
4
5
6
7
8
9
std::shared_ptr<SafeQueue<API::CallbackEvent>> Platform::init_dispatcher(std::shared_ptr<SignalChannel> sig_channel)
{
std::shared_ptr<SafeQueue<API::CallbackEvent>> callback_event_queue = std::make_shared<SafeQueue<API::CallbackEvent>>();
Dispatcher::instance().m_name = "Dispatcher";
Dispatcher::instance().m_queue = callback_event_queue;
Dispatcher::instance().m_sig_channel = sig_channel;
Dispatcher::instance().start();
return callback_event_queue;
}
init_scheduler(…)
Initializes the scheduler component.
try_connect(queue)
Subscribes with the dispatcher for a connection successful event and initiates a new connection with the data source. Shares the event queue with our data source,TWSCallback, so that any new events can be published in the queue, which the dispatcher will poll.
start()
Starts the logger, initializes and starts the dispatcher, and then waits until a connection with the data source has been established before proceeding with the initialization and startup of the scheduler, as well as the registration of the strategies.
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
31
32
33
34
35
36
37
38
39
40
41
42
43
44
45
bool Platform::start()
{
sigset_t sigset;
m_sig_channel = listen_for_sigint(sigset);
start_logger();
std::shared_ptr<SafeQueue<API::CallbackEvent>> callback_event_queue = init_dispatcher(m_sig_channel);
bool succ = try_connect(callback_event_queue, m_sig_channel);
if (!succ)
{
std::stringstream ss;
std::cout << "Unable to connect"<< std::endl;
}
else
{
std::unique_lock connection_lock(Platform::connect_cv_mutex);
Platform::connect_cv.wait_for(
connection_lock,
std::chrono::seconds(30),
[this]()
{
bool should_stop_wait = Platform::connected.load();
return should_stop_wait;
});
if (Platform::connected.load())
{
process_loop();
if (Scheduler::instance().is_running())
{
Scheduler::instance().stop();
Scheduler::instance().join();
}
}
else
{
std::cout << "Connect ack receive timed out" << std::endl;
}
}
Dispatcher::instance().stop();
Dispatcher::instance().join();
stop_logger();
process_loop()
Initializes and starts the scheduler, and proceeds to register the strategies for execution.
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
void Platform::process_loop()
{
init_scheduler(m_sig_channel);
StrategyA strategy_a("Strategy A", m_client);
StrategyB strategy_b("Strategy B", m_client);
std::this_thread::sleep_for(std::chrono::seconds(SLEEP_TIME)); // Sleep for sometime before firing the first request, otherwise we might get a disconnect
Scheduler::instance().register_strategy(&strategy_a);
Scheduler::instance().register_strategy(&strategy_b);
Scheduler::instance().start();
while (!m_sig_channel->m_exit_wait.load())
{
m_client->process_messages();
}
}
Final Thoughts
This brings us to the conclusion of this article. I hope you found it enjoyable and informative. As with some of my other posts, I strive to distill the most important aspects of my project so that you can establish a solid foundation to build upon. I intentionally refrain from discussing cross-cutting concerns such as logging, as this functionality can easily be extracted into a separate module for reuse in different projects, and can be explored in a separate article. Nonetheless, feel free to explore the full implementation on GitHub and tailor it to meet your specific project requirements.