Scraping Stock Purchase Filings from the House of Representatives

Scraping Stock Purchase Filings from the House of Representatives
The United States House of Representatives: a supposedly august body tasked with shaping the nation’s laws. Alongside the Senate, they form a bicameral legislature wielding immense influence over the economy—crafting policies on taxes, regulation, and trade that ripple across industries. Yet behind this veneer of public service lies an inconvenient truth: they wield the power not just to legislate, but to profit.
The 435 members of the House are not just lawmakers; they’re stock traders with an edge that would make even Wall Street blush. Armed with insider information gleaned from their privileged positions, they can act on market-moving intelligence before it becomes public knowledge. Laws set to enrich specific sectors? Regulations that will crush competitors? They know first, and they trade accordingly. Their staggering investment returns surpass not just the average retail trader but even the most lauded financial minds. Warren Buffet might as well be playing checkers.
How do you turn a $200,000 congressional salary into a $200 million net worth? You trade stocks with knowledge no one else has. And the best part? It’s all legal—or at least shielded by disclosure laws so lenient they’re practically a punchline. These laws require members to disclose their trades, but only weeks after the fact, when the real action is long over. Transparency? Barely. Accountability? Laughable.
Here’s a quick visual representation of how much and what stocks some of these magnificent individuals have traded in 2024. It’s a stark reminder of who’s really pulling the strings, and just how much they stand to gain from insider knowledge.
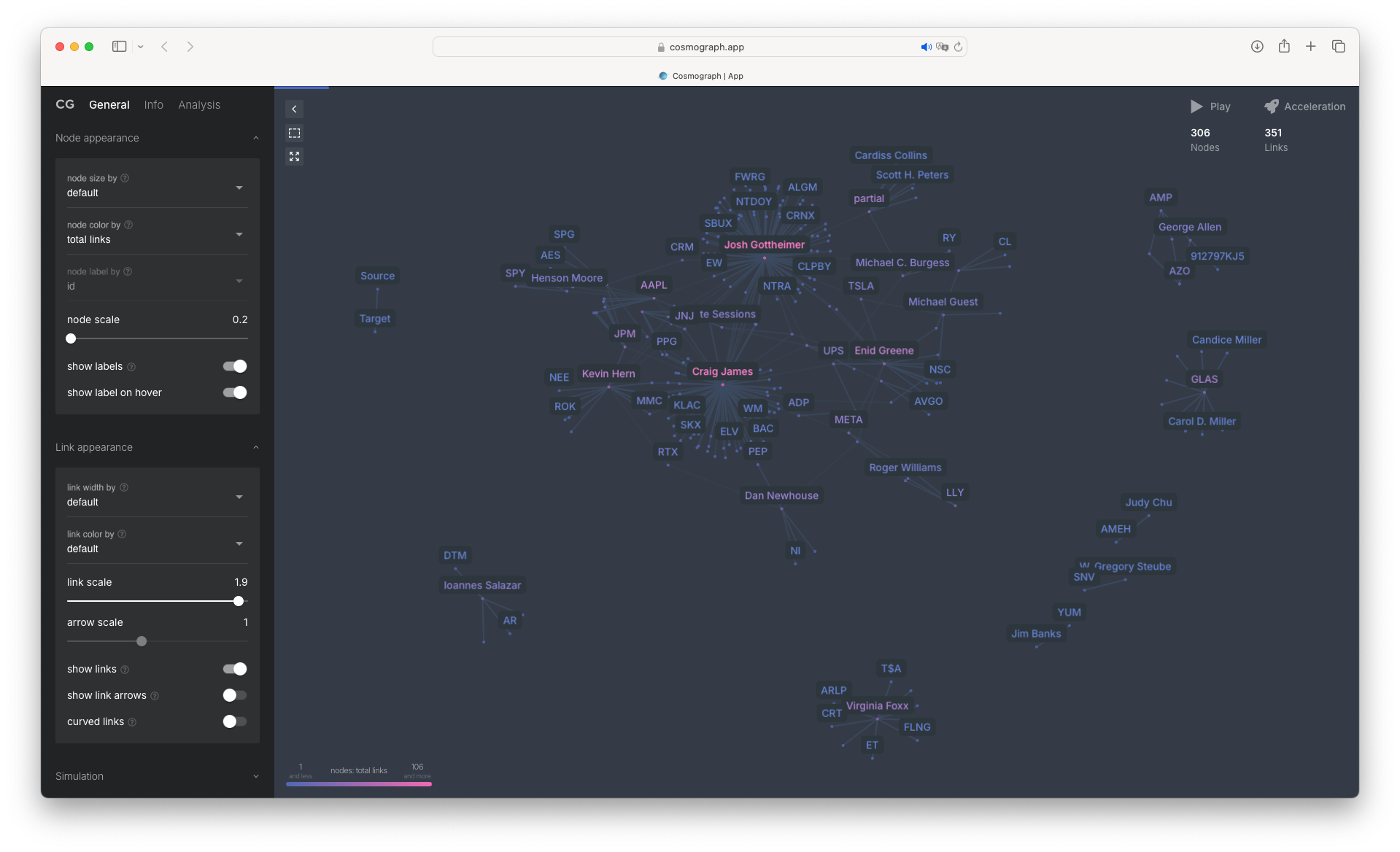
But crumbs are still crumbs, and for those of us outside this gilded circle, tracking these disclosures offers a glimmer of opportunity. With enough vigilance, perhaps we can reverse-engineer their moves, squeezing whatever scraps of profit we can from their ethically dubious windfalls. Because let’s face it: the game is rigged. The least we can do is try to cheat off their homework.
In this post, I’ll walk you through how to automate the collection of congressional stock trading filings—usually buried in PDF format—parse these files, and extract the ticker symbols for the stocks these magnificent specimens have decided to grace with their insider-fueled purchases. We’ll be using Python to handle every step of the process.
And of course, as always, the full source code is available in the GitHub repository linked above. Let’s get started.
Anatomy of the Filings: Breaking Down Congressional Stock Disclosures
The filings are conveniently available online—because even the illusion of transparency needs a paper trail. On the site, you’ll find zip files for each year (e.g.: 2024). I call this the index. It’s a neat little summary: the names of every representative, the type of transaction they executed, and the all-important document ID.
That document ID? It’s our key to the real prize—the actual PDF filing. Because buried in those pages lies the ticker symbols, the bread and butter of this entire operation. Everything else is just window dressing. Let’s dig in.
Here’s a sample disclosure from our beloved Nancy Pelosi—who, at 84 years old and with a full-time job, still finds the time to trade stocks on the side and crush the S&P index like it’s her personal playground. A true multitasking marvel.
Core Concept of Our Python Script
Here’s the game plan for our Python script: First, we’ll download the filing index for the year we’re interested in. This index is essentially a roadmap, listing all the representatives, their transactions, and the document IDs for their filings. Our focus is on a specific list of House representatives—the ones who’ve made insider trading an art form. This list is included in the repository, though it might be outdated by the time you read this. Keep it updated, or better yet, automate the process by scraping it from an official source before running the script.
For every representative name we find in the index, we grab the document ID and fetch the corresponding PDF filing. Each representative gets their own local directory (created if it doesn’t already exist) where we store their PDFs. This way, we avoid downloading duplicates during subsequent runs. The same logic applies to the index file, though since it’s just one file, it’s less of a concern.
Once we have a PDF filing, we process it by OCR parsing it and employing some substring “magic” to extract the ticker symbols disclosed.
1
2
3
4
5
6
7
8
9
10
11
12
def extract_transactions(text_data: str)-> set[str]:
result = set()
content = text_data.split('\n\n')
for line in content:
line = line.replace('\r', '').replace('\n', '')
if line.find(' P ') != -1:
closing_parenthesis = line.find(')')
opening_parenthesis = line.rfind('(', 0, closing_parenthesis)
if closing_parenthesis !=-1 and opening_parenthesis != -1:
ticker = line[opening_parenthesis+1:closing_parenthesis]
result.add(ticker)
return result
If we manage to identify a ticker symbol, we log it into a CSV file containing the representative’s name and the stock they’ve traded. For simplicity, we focus only on purchases—not sales—though tweaking the script to include both is straightforward.
Keep in mind, since we’re tracking only purchases, you won’t know if a representative still holds a position in a stock by the end of the script run.
The Script
First, let’s get the essentials out of the way. We’ll be setting up a virtual environment to keep things clean and contained. Run the following commands:
1
2
3
4
5
6
7
8
9
10
11
# Create a virtual environment
python3 -m venv venv
# Activate the virtual environment
source venv/bin/activate
# Install the required libraries
pip install -r requirements.txt
brew install tesseract
brew install poppler
I’m not going to waste time diving into the nitty-gritty—the code speaks for itself. The point of this post wasn’t to hold your hand through every line of code. It’s about showing you what you can do with a simple Python script. It’s basic scraping, writing results to a CSV—nothing revolutionary, just enough to expose how easy it is to pull back the curtain on the so-called “system.”
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
31
32
33
34
35
36
37
38
39
40
41
42
43
44
45
46
47
48
49
50
51
52
53
54
55
56
57
58
59
60
61
62
63
64
65
66
67
68
69
70
71
72
73
74
75
76
77
78
79
80
81
82
83
84
85
86
87
88
89
90
91
92
93
94
95
96
97
98
99
100
101
102
103
104
105
106
107
108
109
110
111
112
113
114
115
116
117
118
119
120
121
122
123
124
125
126
127
128
129
130
131
132
133
134
135
136
import csv
import zipfile
import requests
import os
import pytesseract
from pdf2image import convert_from_path
# Define global variables
current_year = '2024'
current_directory = os.getcwd()
filings_directory = current_directory + "/" + "downloads"
house_file_path = current_directory + "/" + "house_names.csv"
def read_house(file_path:str) -> set[str]:
result = set()
with open(file_path, newline='') as f:
reader = csv.DictReader(f)
for row in reader:
full_name = row['name']
last_name_idx = full_name.rfind(' ', 0, len(full_name))
last_name = full_name[last_name_idx+1:]
names = (full_name, last_name)
result.add(names)
return sorted(list(result))
def extract_transactions(text_data: str)-> set[str]:
result = set()
content = text_data.split('\n\n')
for line in content:
line = line.replace('\r', '').replace('\n', '')
if line.find(' P ') != -1:
closing_parenthesis = line.find(')')
opening_parenthesis = line.rfind('(', 0, closing_parenthesis)
if closing_parenthesis !=-1 and opening_parenthesis != -1:
ticker = line[opening_parenthesis+1:closing_parenthesis]
result.add(ticker)
return result
def download_and_extract_filing_index() -> str:
new_zipfile_name = filings_directory + "/" + current_year + ".zip"
if os.path.exists(new_zipfile_name):
return
house_zip_url = "https://disclosures-clerk.house.gov/public_disc/financial-pdfs/" + current_year + "FD.ZIP"
print(f"Downloading index '{house_zip_url}'...")
zip_file_request = requests.get(house_zip_url)
# Download and unzip corresponding file
with open(new_zipfile_name, 'wb') as f:
f.write(zip_file_request.content)
with zipfile.ZipFile(new_zipfile_name) as z:
z.extractall(filings_directory)
def download_and_extract_filing_for_represenative(full_name:str, last_name:str):
folder_name = full_name.replace(" ", "_")
doc_id = ''
house_pdf_base_url = "https://disclosures-clerk.house.gov/public_disc/ptr-pdfs/" + current_year + "/"
# Get last name of represenative from user input
represenative_name = last_name
represenative_name = represenative_name.lower() # Convert name to lowercase for directory creation
filing_index_file_path = filings_directory + "/" + f'{current_year}FD.txt'
with open(filing_index_file_path) as f:
for line in csv.reader(f, delimiter='\t'):
if line[1].lower() == represenative_name:
date = line[7]
doc_id = line[8]
# Create directory for represenative if it doesn't exist
represenative_directory_path = filings_directory + "/" + folder_name
if not os.path.exists(represenative_directory_path):
try:
os.makedirs(represenative_directory_path)
except OSError as exc: # Guard against race condition
if exc.errno != zipfile.error.EEXIST:
pass
# Download file if it doesn't exist
represenative_file_path = filings_directory + "/" + folder_name + f"/{doc_id}.pdf"
if not os.path.exists(represenative_file_path):
request_url = f"{house_pdf_base_url}{doc_id}.pdf"
print(f"Downloading '{request_url}' for {full_name}")
pdf_doc_source = requests.get(request_url)
with open(represenative_file_path, 'wb+') as pdf_file:
pdf_file.write(pdf_doc_source.content)
else:
pass
directory = filings_directory + "/" + folder_name
if os.path.isdir(directory):
for file in os.listdir(directory):
if not file.endswith(".pdf"):
continue
file_path = directory + f"/{file}"
# convert to image using resolution 600 dpi
try:
pages = convert_from_path(file_path, 600)
# extract text
text_data = ''
for page in pages:
text = pytesseract.image_to_string(page)
text_data += text + '\n'
tickers = extract_transactions(text_data)
if len(tickers)>0:
print(f"Found stock purchases for: {represenative_name}: {tickers}")
for t in tickers:
write_result([full_name, t, "purchase"])
except Exception as e:
pass
def write_result(line:list[str]):
with open('result.csv', 'a') as myfile:
wr = csv.writer(myfile)
wr.writerow(line)
def main():
last_names = read_house(house_file_path)
download_and_extract_filing_index()
# Create result CSV
write_result(["Source","Target","Relationship"])
for full_name, last_name in last_names:
download_and_extract_filing_for_represenative(full_name, last_name)
if __name__ == "__main__":
main()
You can take the result file, as is, and upload it to Cosmograph. From there, you’ll get a slick, visual breakdown of how much and what stock each representative has traded in the year you care about. No need to complicate things—just dump the data, and let the visualization do the dirty work of exposing the madness.