Building a Poller/Parser/Sender System for Scraping Data in Python

Building a Poller/Parser/Sender System for Scraping Data in Python
In this post, I outline my solution to a challenge I encountered while investing.
To gather the necessary data, I retrieve information from different sources. I need fundamental data, which I get from the SEC, and historical pricing data, which I fetch from Yahoo Finance.
I want my tool to let me specify which stocks I’m interested in and what kind of fundamental data I need (like cash or long-term debt). I also want to choose the time period for the data. Since the data comes in different formats from different sources, my tool needs to organize it into a single format. Finally, I store this data in a relational database like SQLite for future use.
For this project, I used Python and named it Turbine. You can find it on GitHub here. Here’s how I set it up:
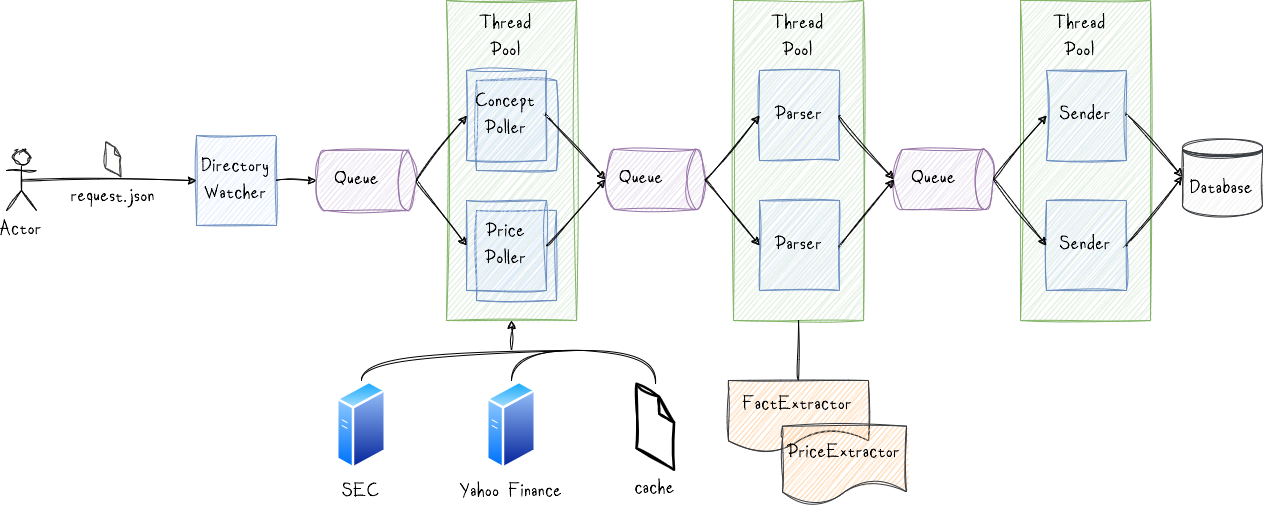
The core components of the framework are the Poller, Parser, and Sender.
DirectoryWatcher
This component monitors the input directory for incoming request.json files, which contain instructions for Turbine on what data to fetch. Below is an example of a request.json file:
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
{
"topic": "concept",
"resources": [
{
"tickers": ["AAPL", "MSFT"],
"concepts": [
{
"name": "AccountsPayableCurrent",
"year": 2014
}
]
},
{
"tickers": ["BIIB"],
"concepts": [
{
"name": "LongTermDebt",
"year": 2014
}
]
}
]
}
Poller
The Poller threads are responsible for connecting to the data source and retrieving information, which could be stored in a database, file system, Web API, etc. Upon retrieval, the data is cached on disk as either JSON or CSV files before being forwarded to the Parser for further processing. Prior to fetching data from the original source, the Pollers check if the requested data is already cached. To initiate a fresh data fetch from the source, it is necessary to delete the contents of the cache directory.
Parser
Parsers handle the data files collected by the Pollers. Their task is to extract relevant information and prepare it for storage. To accomplish this, Parsers dynamically load extractors from disk capable of handling various data formats. The extracted results are then transmitted to the Senders for further action.
Creating custom extractors is straightforward; you can achieve this by subclassing the AbstractExtractor class and placing the file in the extractors folder. Turbine automatically detects these custom extractors upon the next system restart.
Below is an example of an extractor designed to process CSV files:
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
class PriceExtractor(AbstractExtractor):
@overrides(AbstractExtractor)
def supports_input(self, request: DataExtractionRequest):
return request.file_extension and request.file_extension.upper() == ".CSV"
...
@ overrides(AbstractExtractor)
def extract(self, request: DataExtractionRequest):
self.log(f"Proccessing '{request.file}'")
result = []
rows = self._read_rows_from_file(file=request.file)
for row in rows:
try:
result.append(
Price(
ticker=Ticker(symbol=request.ticker),
date=dt.datetime.strptime(row['Date'], "%Y-%m-%d").date(),
open=float(row['Open']),
high=float(row['High']),
low=float(row['Low']),
close=float(row['Close']),
adj_close=float(row['Adj Close']),
volume=float(row['Volume'])
)
)
except Exception as e:
self.log_exception(exception=e)
return result
In the preceding example, the method supports_input(...) serves the purpose of indicating to the framework that this extractor is exclusively compatible with files bearing the extension .csv.
The extract(...) method is expected to yield a list of model objects containing the extracted values.
It is noteworthy that the extractor is equipped with logging capabilities facilitated by self.log(...).
Sender
Sender threads undertake the responsibility of persisting data into an SQLite database.
Additional Features
In addition to the aforementioned core components, various supporting features have been integrated. These include, but are not limited to, the following:
- Configurability: Turbine offers full customization and configuration options. Users can adjust settings such as the implementation of the main components (poller/parser/sender) via a .ini file.
- Logging: Built-in logging functionality is provided, configurable through a .ini file. Any encountered exceptions are automatically caught and logged appropriately.
- Multithreading: Turbine supports multithreading for enhanced performance. Users can specify the number of pollers, parsers, and senders to spawn, with automatic optimization based on available CPU resources.
- Transaction Handler: Users have the flexibility to define custom transaction handling processes. For instance, successful file processing results can be moved to an archive directory, while failed processing attempts can be directed to an error folder. This can be achieved by implementing a custom Transaction Handler, which notifies users upon completion or failure of a poll, enabling tailored processing as needed.
- Monitoring: Turbine can be configured to listen on a designated port. Utilizing the built-in client, users can remotely connect to Turbine and execute basic queries or halt its operation.
Final Thoughts
Although I haven’t delved deeply into implementation specifics, the code becomes quite self-explanatory once you grasp the fundamental landscape and architecture. These systems typically serve as integral components within large enterprise environments, acting as the connective tissue for various extensive production data processing or storage systems. It’s worth noting that while there are existing tools designed to automate the flow of data between software systems, such as Apache NiFi, I personally prefer to develop my own solutions and reinvent the wheel. This preference stems from the realization that third-party solutions may not always align perfectly with one’s specific requirements, potentially leading to roadblocks down the line. Therefore, it’s imperative for a proficient engineer to possess the capability to construct their own frameworks and tools.