Creating an In-Memory Distributed Graph from Scratch with C++

Creating an In-Memory Distributed Graph from Scratch with C++
Recently, while engaged in a project necessitating the analysis of network traffic and user interactions, I encountered a scenario where I was tasked with parsing various forms of network data such as web traffic, chat logs, and email communications. The primary objective of this endeavor is to discern potential connections and correlations among participating users. A typical connection example involves tracing the exchange of emails, where, for instance, John is identified as having corresponded with Bob, thereby establishing a relationship between them. Furthermore, connections can also be inferred between user identifiers that plausibly belong to the same individual, such as a social media username and an email address utilized for registration purposes.
Utilizing a graph representation to visualize these relationships appears to be a fitting conceptual framework for this task. Here, each unique user ID serves as an individual node or vertex within the graph structure, while the presence of an edge between distinct vertices signifies a connection or relationship between corresponding users.
While numerous graph databases and frameworks exist in the market, my decision to embark on constructing my own in-memory graph stemmed from a combination of personal enjoyment and specific requirements. There are two kinds of people in the world: those proficient in the construction of software frameworks, and those solely adept at their utilization. I wanted the flexibility to perform basic queries, such as searching for an ID and then exploring its immediate and subsequent connections within the graph. I aimed to ensure efficient space utilization by distributing the graph across multiple machines. Each machine would host a portion of the graph, thereby optimizing resource allocation and scalability.
The comprehensive source code is accessible through the project’s GitHub repository. Minimal attention will be devoted to cross-cutting concerns such as logging and mock data generation. Instead, emphasis will be placed on elucidating primary concepts, notably the graph and its corresponding API.
Let’s commence.
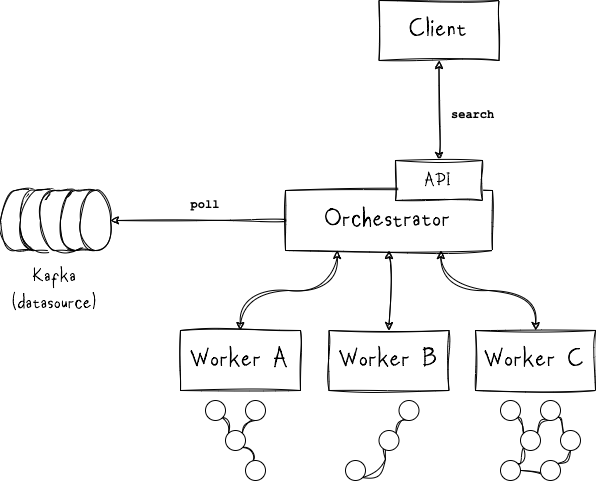
Landscape & Main Components
The system will comprise two distinct categories of components: Worker nodes, each of which retains a subgraph segment within the distributed graph, and an Orchestrator node tasked with the distribution of data, including new vertices and edges, across the worker nodes using a hashing mechanism. Additionally, the orchestrator assumes responsibility for handling client queries, such as searches for specific nodes and their neighboring nodes within the graph. While multiple worker nodes may exist, only one orchestrator node is permissible. Both the worker nodes and the orchestrator operate as separate processes within the system architecture.
Each of these processes can be initiated using the following commands:
1
2
3
4
5
6
7
# Start 2 worker nodes
./src/build/graph_worker -c configs/worker_A.yaml
./src/build/graph_worker -c configs/worker_B.yaml
./src/build/graph_worker -c configs/worker_C.yaml
# Start the orchestrator
./src/build/main -c configs/orchestrator.yaml
Orchestrator
As previously noted, the orchestrator assumes multiple responsibilities within the system architecture. It serves as the central application, encompassing distinct functionalities such as data distribution—encompassing new vertices and edges—and the management of client queries. Additionally, the orchestrator operates a separate thread dedicated to retrieving graph data from a designated source such as Kafka, which subsequently undergoes distribution to the worker nodes. Furthermore, the orchestrator conducts health checks on the graph cluster’s status. Notably, it operates an API that facilitates connections for third-party clients, enabling them to query the graph. Both the API functionality and the communication between the orchestrator and worker nodes are implemented using gRPC technology.
Worker
The worker nodes are responsible for managing subsets of nodes and edges from the entire graph. Allocation of nodes and edges to each worker is determined by the orchestrator through a hash-based mechanism. Upon receiving new vertices or edges, the orchestrator computes their hash values and forwards them to the designated worker node. Subsequently, each worker node constructs an in-memory graph containing the received data elements.
Similarly, queries are handled within this distributed architecture. Upon receiving a node search query, the orchestrator computes its hash to determine the appropriate worker node for the initial search. If the query requires fetching neighboring nodes up to a specified level, a breadth-first search is initiated from the queried node. To accomplish this, each worker node must be aware of others within the cluster to facilitate query forwarding to relevant workers holding pertinent parts of the graph. Results are then aggregated and returned to the requesting client.
HealthChecker
The HealthChecker primarily conducts reachability checks on the worker nodes. Its role is integral within the system, as it enables the orchestrator to verify the operational status of all worker nodes prior to initiating data retrieval from the designated source and commencing distribution tasks.
Implementation
gRPC Stubs
Protocol Buffers serve as a language-agnostic and platform-independent means of serializing structured data. In essence, they provide a mechanism akin to JSON, albeit with the advantages of being more compact and faster, while also facilitating the generation of native language bindings. This is achieved by initially defining the desired data structure in a .proto file, followed by the utilization of specialized generated source code to seamlessly write and read structured data across diverse data streams and programming languages.
A complete implementation of Protocol Buffers encompasses several components:
- The definition language, housed in .proto files, outlining the structure of the data.
- The code generated by the proto compiler, which interfaces with the data.
- Language-specific runtime libraries.
- The serialization format for data written to files or transmitted across network connections.
In the context of gRPC, Protocol Buffers are employed in conjunction with a specialized gRPC plugin for protoc. This facilitates the generation of code from the proto file, yielding both gRPC client and server code alongside the conventional protocol buffer code. This generated code facilitates tasks such as populating, serializing, and retrieving message types. For comprehensive insights into Protocol Buffers, including instructions on installing protoc with the gRPC plugin in your preferred programming language, refer to the protocol buffers documentation.
Lets define our graph gRPC services in ordinary proto files, with RPC method parameters and return types specified as protocol buffer messages. First, we shall establish the parameters and return types for the RPC methods in orchestrator-worker communication. In essence, this pertains to our internal cluster communication protocol.
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
31
32
33
34
35
36
37
38
39
40
41
42
43
44
45
46
47
48
49
50
51
52
53
54
55
56
57
58
59
60
61
62
/* graph.proto */
syntax = "proto3";
import "google/protobuf/empty.proto";
package graph;
service Graph {
rpc AddHost(Host) returns (google.protobuf.Empty) {}
rpc AddVertex(stream Vertex) returns (GraphSummary) {}
rpc DeleteVertex(stream Vertex) returns (GraphSummary) {}
rpc AddEdge(stream Edge) returns (GraphSummary) {}
rpc DeleteEdge(stream Edge) returns (GraphSummary) {}
rpc Search(SearchArgs) returns (SearchResults) {}
rpc Ping(PingRequest) returns (PingResponse) {}
}
message Host {
string key = 1;
string address = 2;
}
message Vertex {
string key = 1;
string value = 2;
}
message Edge {
string from = 1;
string to = 2;
string label = 3;
string lookup_from = 4;
string lookup_to = 5;
string key = 6;
}
message GraphSummary {
int32 vertex_count = 1;
int32 edge_count = 2;
}
message SearchArgs {
string start_key = 1;
int32 level = 2;
repeated Vertex vertices = 3;
repeated Edge edges = 4;
repeated string ids_so_far = 5;
}
message SearchResults {
repeated Vertex vertices = 1;
repeated Edge edges = 2;
repeated string ids_so_far = 3;
}
message PingRequest {
string data = 1;
}
message PingResponse {
string data = 1;
}
Subsequently, we proceed to define the Protocol Buffers for the RPC API intended for end clients. This refers to the user-facing API.
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
31
32
33
34
35
36
37
38
39
40
41
42
/* orchestrator.proto */
syntax = "proto3";
import "google/protobuf/empty.proto";
package orchestrator;
service Orchestrator {
rpc AddVertex(stream ApiVertex) returns (ApiGraphSummary) {}
rpc DeleteVertex(stream ApiVertex) returns (ApiGraphSummary) {}
rpc AddEdge(stream ApiEdge) returns (ApiGraphSummary) {}
rpc DeleteEdge(stream ApiEdge) returns (ApiGraphSummary) {}
rpc Search(ApiSearchArgs) returns (ApiSearchResults) {}
}
message ApiVertex {
string key = 1;
string value = 2;
}
message ApiEdge {
string from = 1;
string to = 2;
string label = 3;
string key = 4;
}
message ApiGraphSummary {
int32 vertex_count = 1;
int32 edge_count = 2;
}
message ApiSearchArgs {
string query_key = 1;
int32 level = 2;
}
message ApiSearchResults {
repeated ApiVertex vertices = 1;
repeated ApiEdge edges = 2;
}
Lastly, we will generate the stubs utilizing the provided shell script.
1
2
3
4
5
6
7
8
9
10
# make-proto
#!/bin/bash
cd src
mkdir -p build
cd build
cmake cmake -DCMAKE_PREFIX_PATH=~/opt/grpc -DCMAKE_CXX_STANDARD=20 ..
make graph.grpc.pb.o
make orchestrator.grpc.pb.o
Datasource Interface
Let’s begin by creating a data source interface. This interface will act as a middle layer for our orchestrator, Kafka connector, and health checker. These components require the ability to retrieve data from a source, making a structured interface essential for smooth communication and functionality.
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
/* data_source.h */
#ifndef DATA_SOURCE_H
#define DATA_SOURCE_H
#include <memory>
class DataSource {
protected:
int m_poll_interval = 10;
virtual void Query() = 0;
public:
virtual ~DataSource(){};
int NextPollInterval() const { return m_poll_interval; }
void Poll() { this->Query(); }
virtual void Stop() = 0;
};
#endif
Every component inheriting from this class must override the Query() method, implementing the specific data retrieval logic. Subsequently, a concrete data source object will be handed over to a thread dispatcher object. This dispatcher will periodically invoke the Poll() method at the designated interval within a distinct thread in order to fetch new data.
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
31
32
33
34
35
36
37
38
39
40
41
42
43
44
45
46
47
48
49
50
51
52
53
54
55
56
57
58
59
60
61
62
63
64
65
66
67
68
69
70
71
72
73
74
75
76
/* thread_dispatcher.h */
#ifndef THREAD_DISPATCHER_H
#define THREAD_DISPATCHER_H
#include <iostream>
#include <memory>
#include <thread>
#include "data_source.h"
#include "logging/log_signal.h"
class SignalChannel;
class ThreadDispatcher {
private:
std::shared_ptr<DataSource> m_producer;
std::thread m_thread;
std::shared_ptr<SignalChannel> m_sig_channel;
std::shared_ptr<LogSignal> m_log_signal;
static void Loop(ThreadDispatcher *self) {
std::shared_ptr<DataSource> producer = self->m_producer;
while (!self->m_sig_channel->m_shutdown_requested.load()) {
{
// Lock first, then check predicate, if false unlock and then wait
std::unique_lock lock(self->m_sig_channel->m_cv_mutex);
/*
When it wakes up it tries to re-lock the mutex and check the
predicate.
*/
self->m_sig_channel->m_cv.wait_for(lock,
// wait for up to 5 milliseconds
std::chrono::milliseconds(5),
// when the condition variable is woken up and this predicate
// returns true, the wait is stopped:
[&self]() {
bool stop_waiting =
self->m_sig_channel->m_shutdown_requested.load();
return stop_waiting;
});
if (self->m_sig_channel->m_shutdown_requested.load()) {
break;
}
} // wait() reacquired the lock on exit. So we release it here since there is no reason to hold it while
// polling.
{
std::unique_lock lock(self->m_log_signal->m_log_mutex);
self->m_log_signal->active_processors.fetch_add(1);
}
producer->Poll();
{
std::unique_lock lock(self->m_log_signal->m_log_mutex);
self->m_log_signal->active_processors.fetch_add(-1);
}
auto delay = std::chrono::milliseconds(producer->NextPollInterval());
std::this_thread::sleep_for(delay);
}
std::cout << "ThreadDispatcher shutting down:" << self->m_sig_channel->m_shutdown_requested.load() << std::endl;
producer->Stop();
}
public:
explicit ThreadDispatcher(std::shared_ptr<DataSource> p, std::shared_ptr<SignalChannel> s,
std::shared_ptr<LogSignal> log_signal)
: m_producer(p), m_sig_channel(s), m_log_signal(log_signal), m_thread(Loop, this) {}
~ThreadDispatcher() { m_thread.join(); }
};
#endif
Kafka Datasource
Now that we have defined our DataSource interface, let’s proceed with implementing a concrete data source: our Kafka data source.
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
31
32
33
34
35
36
37
38
39
40
/* kafka_data_source.h */
#ifndef KAFKA_DATA_SOURCE_H
#define KAFKA_DATA_SOURCE_H
#include <rdkafkacpp.h>
#include <map>
#include <memory>
#include <string>
#include <vector>
#include "../data_source.h"
#include "kafka_delivery_report_cb.h"
#include "kafka_message_strategy.h"
class KafkaBuilder;
class KafkaDataSource : public DataSource {
private:
std::string m_name;
std::string m_bootstrap_servers;
std::string m_client_id;
std::string m_group_id;
std::unique_ptr<KafkaDeliveryReportCb> m_delivery_report_callback;
std::vector<std::string> m_topics;
RdKafka::KafkaConsumer* m_kafka_consumer;
std::unique_ptr<KafkaMessageStrategy> m_kafka_strategy;
protected:
void Query() override;
public:
~KafkaDataSource();
void Stop() override;
friend class KafkaBuilder;
};
#endif
Below is the corresponding definition for our Kafka data source:
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
/* kafka_data_source.cc */
#include "kafka_data_source.h"
#include <rdkafkacpp.h>
#include <signal.h> // kill()
#include <unistd.h> // getpid()
#include <iostream>
#include "kafka_delivery_report_cb.h"
#include "kafka_message_strategy.h"
#include "kafka_print_message_strategy.h"
void KafkaDataSource::Query() {
RdKafka::Message *message = m_kafka_consumer->consume(0);
m_kafka_strategy->Run(message, NULL);
delete message;
}
void KafkaDataSource::Stop() {
std::cout << m_name << " stopping" << std::endl;
m_kafka_consumer->close();
delete m_kafka_consumer;
RdKafka::wait_destroyed(5000);
std::cout << m_name << " stopped" << std::endl;
}
KafkaDataSource::~KafkaDataSource() {}
The Kafka delivery report callback (i.e. KafkaDeliveryReportCb) serves the purpose of signaling back to the application upon the successful delivery of a message, or in cases where delivery has failed permanently despite retries.
1
2
3
4
5
6
7
8
9
10
11
12
13
/* kafka_delivery_report_cb.h */
#ifndef KAFKA_DELIVERY_REPORT_CB_H
#define KAFKA_DELIVERY_REPORT_CB_H
#include <rdkafkacpp.h>
class KafkaDeliveryReportCb : public RdKafka::DeliveryReportCb {
public:
void dr_cb(RdKafka::Message &message);
};
#endif
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
/* kafka_delivery_report_cb.cc */
#include "kafka_delivery_report_cb.h"
#include <iostream>
static std::string name = "KafkaDeliveryReportCb";
void KafkaDeliveryReportCb::dr_cb(RdKafka::Message &message) {
if (message.err()) {
std::cout << name << ": Message publication failed: " << message.errstr();
} else {
std::cout << name << ": Message published to topic " << message.topic_name() << " ["
<< std::to_string(message.partition()) << "] at offset " << std::to_string(message.offset());
}
}
As you may have observed, we have implemented the Strategy Design Pattern to manage incoming messages effectively. Below, you will find the corresponding interface and definitions for this pattern:
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
/* kafka_message_strategy.h */
#ifndef KAFKA_MESSAGE_STRATEGY_H
#define KAFKA_MESSAGE_STRATEGY_H
#include <rdkafkacpp.h>
#include <memory>
class KafkaMessageStrategy {
public:
KafkaMessageStrategy(std::string name) : m_name(name) {}
virtual void Run(RdKafka::Message *message, void *opaque) const = 0;
virtual ~KafkaMessageStrategy() = default;
protected:
std::string m_name;
};
#endif
An exhaustive strategy that we will employ in this example is listed below. A critical aspect here is the LockFreeQueue member variable, which the Kafka strategy will utilize to push fetched messages into. This queue will be shared with the orchestrator, which in turn will consume these messages and distribute the data to the workers.
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
/* kafka_print_message_strategy.h */
#ifndef KAFKA_PRINT_MESSAGE_STRATEGY_H
#define KAFKA_PRINT_MESSAGE_STRATEGY_H
#include <rdkafkacpp.h>
#include <string>
#include "../lock_free_queue.h"
#include "kafka_message_strategy.h"
#include "kafka_strategy_factory.h"
class KafkaPrintMessageStrategy : public KafkaMessageStrategy {
private:
REGISTER_DEC_TYPE(KafkaPrintMessageStrategy);
public:
std::shared_ptr<LockFreeQueue<std::string>> m_output_queue;
public:
using KafkaMessageStrategy::KafkaMessageStrategy;
void Run(RdKafka::Message *message, void *opaque) const override;
};
#endif
The REGISTER_DEC_TYPE macro might ring a bell. We delved into it extensively in a prior discussion.
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
31
32
33
34
35
36
37
38
39
40
41
42
43
44
45
46
47
48
49
/* kafka_print_message_strategy.cc */
#include "kafka_print_message_strategy.h"
#include <iostream>
#include "../logging/logging.h"
REGISTER_DEF_TYPE(KafkaPrintMessageStrategy, PrintType);
void KafkaPrintMessageStrategy::Run(RdKafka::Message *message, void *opaque) const {
switch (message->err()) {
case RdKafka::ERR__TIMED_OUT:
break;
case RdKafka::ERR_NO_ERROR:
/* Real message */
Logging::DEBUG("Read msg at offset " + std::to_string(message->offset()), m_name);
RdKafka::MessageTimestamp ts;
ts = message->timestamp();
if (ts.type != RdKafka::MessageTimestamp::MSG_TIMESTAMP_NOT_AVAILABLE) {
std::string tsname = "?";
if (ts.type == RdKafka::MessageTimestamp::MSG_TIMESTAMP_CREATE_TIME)
tsname = "create time";
else if (ts.type == RdKafka::MessageTimestamp::MSG_TIMESTAMP_LOG_APPEND_TIME)
tsname = "log append time";
Logging::DEBUG("Timestamp: " + tsname + " " + std::to_string(ts.timestamp), m_name);
}
if (message->key()) {
Logging::DEBUG("Key: " + *message->key(), m_name);
}
Logging::DEBUG("Payload: " + std::string(static_cast<const char *>(message->payload())), m_name);
m_output_queue->Push(std::string(static_cast<const char *>(message->payload())));
break;
case RdKafka::ERR__PARTITION_EOF:
Logging::ERROR("EOF reached for all partition(s)", m_name);
break;
case RdKafka::ERR__UNKNOWN_TOPIC:
case RdKafka::ERR__UNKNOWN_PARTITION:
Logging::ERROR("Consume failed: " + message->errstr(), m_name);
break;
default:
/* Errors */
Logging::ERROR("Consume failed: " + message->errstr(), m_name);
}
}
To finalize the Kafka data source, let’s proceed with creating a Kafka builder to facilitate the creation of new instances.
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
31
32
33
34
35
36
37
/* kafka_builder.h */
#ifndef KAFKA_BUILDER_H
#define KAFKA_BUILDER_H
#include <memory>
#include <string>
#include <vector>
#include "kafka_data_source.h"
#include "kafka_delivery_report_cb.h"
class KafkaMessageStrategy;
class KafkaBuilder {
private:
std::string m_name;
std::string m_bootstrap_servers;
std::string m_client_id;
std::string m_group_id;
std::unique_ptr<KafkaDeliveryReportCb> m_delivery_report_callback;
std::vector<std::string> m_topics;
std::unique_ptr<KafkaMessageStrategy> m_kafka_strategy;
public:
KafkaBuilder();
KafkaBuilder& WithName(std::string v);
KafkaBuilder& WithBootstrapServers(std::string v);
KafkaBuilder& WithClientId(std::string v);
KafkaBuilder& WithGroupId(std::string v);
KafkaBuilder& WithDeliveryReportCallback(std::unique_ptr<KafkaDeliveryReportCb> v);
KafkaBuilder& WithTopics(std::vector<std::string> v);
KafkaBuilder& WithKafkaMessageStrategy(std::unique_ptr<KafkaMessageStrategy> v);
std::unique_ptr<KafkaDataSource> Build();
};
#endif
Additionally, let’s provide the accompanying definitions.
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
31
32
33
34
35
36
37
38
39
40
41
42
43
44
45
46
47
48
49
50
51
52
53
54
55
56
57
58
59
60
61
62
63
64
65
66
67
68
69
70
71
72
73
74
75
76
77
78
79
80
81
82
83
84
85
86
87
88
89
90
91
92
93
94
95
96
97
98
99
100
101
102
103
104
105
106
107
108
109
110
111
112
113
114
115
116
117
118
119
120
121
/* kafka_builder.cc */
#include "kafka_builder.h"
#include <rdkafkacpp.h>
#include <signal.h> // kill()
#include <unistd.h> // getpid()
#include <iostream>
KafkaBuilder::KafkaBuilder() {}
KafkaBuilder& KafkaBuilder::WithName(std::string v) {
m_name = v;
return *this;
}
KafkaBuilder& KafkaBuilder::WithBootstrapServers(std::string v) {
m_bootstrap_servers = v;
return *this;
}
KafkaBuilder& KafkaBuilder::WithClientId(std::string v) {
m_client_id = v;
return *this;
}
KafkaBuilder& KafkaBuilder::WithGroupId(std::string v) {
m_group_id = v;
return *this;
}
KafkaBuilder& KafkaBuilder::WithDeliveryReportCallback(std::unique_ptr<KafkaDeliveryReportCb> v) {
m_delivery_report_callback = std::move(v);
return *this;
}
KafkaBuilder& KafkaBuilder::WithTopics(std::vector<std::string> v) {
m_topics = v;
return *this;
}
KafkaBuilder& KafkaBuilder::WithKafkaMessageStrategy(std::unique_ptr<KafkaMessageStrategy> v) {
m_kafka_strategy = std::move(v);
return *this;
}
std::unique_ptr<KafkaDataSource> KafkaBuilder::Build() {
if (m_name.empty()) {
m_name = "Kafka";
}
if (m_bootstrap_servers.empty()) {
throw std::runtime_error("No bootstrap servers provided");
}
if (m_client_id.empty()) {
throw std::runtime_error("No client id provided");
}
if (m_group_id.empty()) {
throw std::runtime_error("No group id provided");
}
if (!m_delivery_report_callback) {
throw std::runtime_error("No delivery report callback provided");
}
if (m_topics.empty()) {
throw std::runtime_error("No topics provided");
}
if (!m_kafka_strategy) {
throw std::runtime_error("No Kafka strategy provided");
}
std::unique_ptr<KafkaDataSource> kafka = std::make_unique<KafkaDataSource>();
kafka->m_name = std::move(m_name);
kafka->m_bootstrap_servers = std::move(m_bootstrap_servers);
kafka->m_client_id = std::move(m_client_id);
kafka->m_group_id = std::move(m_group_id);
kafka->m_delivery_report_callback = std::move(m_delivery_report_callback);
kafka->m_topics = std::move(m_topics);
kafka->m_kafka_strategy = std::move(m_kafka_strategy);
RdKafka::Conf* conf = RdKafka::Conf::create(RdKafka::Conf::CONF_GLOBAL);
std::string errstr;
if (conf->set("bootstrap.servers", kafka->m_bootstrap_servers, errstr) != RdKafka::Conf::CONF_OK) {
std::cout << errstr;
kill(getpid(), SIGINT);
}
if (conf->set("client.id", kafka->m_client_id, errstr) != RdKafka::Conf::CONF_OK) {
std::cout << errstr;
kill(getpid(), SIGINT);
}
if (conf->set("group.id", kafka->m_group_id, errstr) != RdKafka::Conf::CONF_OK) {
std::cout << errstr;
kill(getpid(), SIGINT);
}
if (conf->set("dr_cb", kafka->m_delivery_report_callback.get(), errstr) != RdKafka::Conf::CONF_OK) {
std::cout << errstr;
kill(getpid(), SIGINT);
}
RdKafka::KafkaConsumer* kafka_consumer = RdKafka::KafkaConsumer::create(conf, errstr);
if (!kafka_consumer) {
std::cout << "Failed to create Kafka consumer: " << errstr;
kill(getpid(), SIGINT);
}
RdKafka::ErrorCode err = kafka_consumer->subscribe(kafka->m_topics);
if (err) {
std::cerr << "Failed to subscribe to " << kafka->m_topics.size() << " topics" << RdKafka::err2str(err)
<< std::endl;
kill(getpid(), SIGINT);
}
kafka->m_kafka_consumer = kafka_consumer;
delete conf;
return kafka;
}
A comprehensive documentation of the Apache Kafka C/C++ client library can be found here.
Finally, let’s explore how we can initialize and activate our Kafka data source.
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
/* main.cc */
// ...
std::shared_ptr<LockFreeQueue<std::string>> graph_queue = std::make_shared<LockFreeQueue<std::string>>();
// ...
std::map<std::string, std::string> kafka_config = config.kafka();
std::unique_ptr<KafkaMessageStrategy> ptr = KafkaFactory::GetInstance("PrintType", "Printer");
dynamic_cast<KafkaPrintMessageStrategy*>(ptr.get())->m_output_queue = graph_queue;
std::shared_ptr<KafkaDataSource> kafka =
KafkaBuilder()
.WithName("Kafka")
.WithBootstrapServers(kafka_config["bootstrap.servers"])
.WithClientId(kafka_config["client.id"])
.WithGroupId("foo")
.WithDeliveryReportCallback(std::move(std::make_unique<KafkaDeliveryReportCb>()))
.WithTopics({"graph_data"})
.WithKafkaMessageStrategy(std::move(ptr))
.Build();
ThreadDispatcher kafka_poller(kafka, sig_channel, log_signal);
// ...
I won’t delve deeply into the KafkaFactory, as it closely resembles the factory discussed in one of my previous posts. Moreover, the complete source code is readily available in the linked GitHub repository.
Orchestrator Classes
Let’s proceed with the orchestration classes, which serve as the foundational components of my cluster architecture.
Similar to our Kafka connector component, the orchestrator also inherits from DataSource, as it will poll messages from the input queue—refer to the Kafka message strategy mentioned earlier—which the Kafka data source is writing into.
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
31
32
33
34
35
36
37
38
39
40
41
42
43
/* graph_orchestrator.h */
#ifndef GRAPH_ORCHESTRATOR_H
#define GRAPH_ORCHESTRATOR_H
#include <atomic>
#include <memory>
#include <string>
#include <vector>
#include "../data_source.h"
#include "../lock_free_queue.h"
#include "graph_client.h"
class OrchestratorBuilder;
class GraphOrchestrator : public DataSource {
private:
std::string m_name;
std::vector<GraphClient> m_worker_clients;
std::vector<std::string> m_worker_address;
std::shared_ptr<std::atomic<size_t>> m_active_processors;
std::shared_ptr<LockFreeQueue<std::string>> m_input_queue;
std::atomic<bool> m_healthy;
protected:
void Query() override;
public:
GraphOrchestrator(std::string name_);
void AddVertex(std::string key, std::string data);
void AddEdge(std::string from, std::string to, std::string data);
Status Search(std::string query_key, int level, std::vector<std::string>& vertices,
std::vector<std::string>& edges);
void Init();
void Ping();
bool Healthy();
void Stop() override;
friend class OrchestratorBuilder;
};
#endif
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
31
32
33
34
35
36
37
38
39
40
41
42
43
44
45
46
47
48
49
50
51
52
53
54
55
56
57
58
59
60
61
62
63
64
65
66
67
68
69
70
71
72
73
74
75
76
77
78
79
80
81
82
83
84
85
86
87
88
89
90
91
92
93
94
95
96
97
98
99
100
101
102
103
104
105
106
107
108
109
110
111
112
113
114
115
116
117
118
119
120
121
122
123
124
125
126
127
128
129
130
131
132
133
134
135
136
137
138
139
140
141
142
143
144
145
146
147
148
149
150
151
152
153
/* graph_orchestrator.cc */
#include "graph_orchestrator.h"
#include <grpc/grpc.h>
#include <grpcpp/channel.h>
#include <grpcpp/client_context.h>
#include <grpcpp/create_channel.h>
#include <grpcpp/security/credentials.h>
#include <functional> //for std::hash
#include <iostream>
#include <memory>
#include <nlohmann/json.hpp>
#include <random>
#include <string>
#include <vector>
#include "../graph/helper.h"
#include "../graph/in_memory_graph.h"
#include "../grpc/graph.grpc.pb.h"
#include "../logging/logging.h"
#include "graph_client.h"
using graph::Edge;
using graph::Graph;
using graph::Host;
using graph::SearchResults;
using graph::Vertex;
using grpc::Channel;
GraphOrchestrator::GraphOrchestrator(std::string name_) : m_name(name_) {}
void GraphOrchestrator::AddVertex(std::string key, std::string data) {
std::hash<std::string> hasher;
auto hashed = hasher(key);
int worker_index = hashed % m_worker_clients.size();
Logging::DEBUG("Pushing vertex '" + key + "' to worker '" + m_worker_address[worker_index] + "'", m_name);
m_worker_clients[worker_index].AddVertices(InMemoryGraph<std::string, std::string>::InMemoryVertex(key, data));
}
void GraphOrchestrator::AddEdge(std::string from, std::string to, std::string label) {
std::hash<std::string> hasher;
auto from_worker_hashed = hasher(from);
int from_worker_index = from_worker_hashed % m_worker_clients.size();
auto lookup_to_worker_hashed = hasher(to);
int lookup_to_worker_index = lookup_to_worker_hashed % m_worker_clients.size();
Logging::INFO("Push edge [" + from + "][" + label + "][" + to + "] to worker '" +
std::to_string(from_worker_index) + "' with lookup_to: '" +
std::to_string(lookup_to_worker_index) + "' (" + m_worker_address[lookup_to_worker_index] + ")",
m_name);
InMemoryGraph<std::string, std::string>::InMemoryVertex from_vertex(from, from);
InMemoryGraph<std::string, std::string>::InMemoryEdge edge(to, label, m_worker_address[lookup_to_worker_index]);
m_worker_clients[from_worker_index].AddEdges(from_vertex, edge, m_worker_address[from_worker_index]);
}
bool GraphOrchestrator::Healthy() { return m_healthy.load(); }
void GraphOrchestrator::Init() {
/*************************************************************************
*
* ADVERTISE HOSTS
*
*************************************************************************/
for (const auto& address : m_worker_address) {
for (const auto& worker : m_worker_clients) {
worker.AddHost(address, address);
}
}
}
void GraphOrchestrator::Query() {
std::shared_ptr<std::string> payload = m_input_queue->Pop();
if (payload) {
Logging::INFO("Got " + *payload, m_name);
while (!Healthy()) {
Logging::ERROR("Graph doesn't seem to be healthy. Not attemping to add node", m_name);
}
/*
{"from": "a","to": "b","label": "friend"}
*/
using json = nlohmann::json;
try {
json data = json::parse(*payload);
std::string from = data.at("from");
std::string to = data.at("to");
std::string label = data.at("label");
AddVertex(from, from);
AddVertex(to, to);
AddEdge(from, to, label);
} catch (...) {
Logging::ERROR("Malformed payload: '" + *payload + "'", m_name);
}
}
}
void GraphOrchestrator::Stop() { Logging::INFO("Stopping", m_name); }
void GraphOrchestrator::Ping() {
// Not thread safe!
bool ok = true;
for (const auto& worker : m_worker_clients) {
ok = worker.Ping();
if (!ok) {
break;
}
}
if (ok) {
m_healthy.store(true);
} else {
m_healthy.store(false);
}
}
/*
*************************************************************************
* USER FACING API
*************************************************************************
*/
Status GraphOrchestrator::Search(std::string query_key, int level, std::vector<std::string>& vertices,
std::vector<std::string>& edges) {
SearchResults result;
std::hash<std::string> hasher;
auto hashed = hasher(query_key);
int worker_index = hashed % m_worker_clients.size();
Logging::INFO("Start search vertex '" + query_key + "' with at: '" + std::to_string(worker_index) + "' (" +
m_worker_address[worker_index] + ")",
m_name);
Status status = m_worker_clients[worker_index].Search(query_key, level, result);
if (!status.ok()) {
Logging::ERROR("Search rpc failed", m_name);
} else {
for (auto& v : result.vertices()) {
vertices.emplace_back(v.key());
}
for (auto& e : result.edges()) {
edges.emplace_back(e.label());
}
}
return status;
}
That’s a substantial amount of code. Let’s proceed with a concise overview of the primary functions.
Init()
Here, the orchestrator disseminates information about each worker to all other workers within the cluster.
Query()
Much like the Kafka data source, the orchestrator must implement this method. It simply polls from the shared message queue, disassembles any polled message into vertices and edges, and then distributes these elements across the cluster to update the distributed graph using theAddVertex(...)andAddEdge(...)methods..
Ping()
A straightforward health check method that involves the orchestrator pinging each worker node and waiting for a response. If every worker responds, the cluster is deemed healthy.
AddVertex(key, data)
This component is part of the internal communication API within the cluster. It adds a new vertex to the graph, incorporating the provided key and data.
AddEdge(from, to, label)
This component is part of the internal communication API within the cluster. It adds a new unidirectional edge that connects the from and to nodes in the graph, with the associated label.
Search(key, level, vertices, edges)
This section pertains to the user-facing API. The method triggers a search on the cluster for the node with the specified key and returns the matching vertex, along with any associated edges and neighboring vertices up to a specified level from the found node.
Let’s proceed with the implementation of the gRPC service. We’ve already generated the gRPC service stubs and interfaces, such as Orchestrator::Service. Now it’s time to provide a proprietary implementation of this interface. This service implementation is necessary for the gRPC ApiRunner to initiate the gRPC service, accept connections, and handle RPC calls. Essentially, it serves as the user-facing API that accepts and handles new requests. Any incoming RPC requests will be forwarded to the orchestrator member object, which will then, if necessary, forward them to the workers.
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
31
32
33
34
35
36
37
38
39
40
41
42
43
44
45
46
47
48
49
50
51
52
53
54
55
56
57
58
59
60
61
62
63
64
65
66
67
68
69
70
71
72
73
74
75
76
77
78
79
80
81
82
83
84
85
86
87
88
89
90
91
92
93
94
95
96
97
98
99
100
101
102
103
104
105
106
107
108
109
110
111
112
113
114
115
116
/* orchestrator_api.h */
#ifndef ORCHESTRATOR_API_H
#define ORCHESTRATOR_API_H
#include <grpc/grpc.h>
#include <grpcpp/create_channel.h>
#include <grpcpp/security/server_credentials.h>
#include <grpcpp/server.h>
#include <grpcpp/server_builder.h>
#include <grpcpp/server_context.h>
#include <memory>
#include <string>
#include "../grpc/orchestrator.grpc.pb.h"
#include "graph_orchestrator.h"
#include "logging/logging.h"
using grpc::Server;
using grpc::ServerBuilder;
using grpc::ServerContext;
using grpc::ServerReader;
using grpc::ServerReaderWriter;
using grpc::ServerWriter;
using grpc::Status;
using std::chrono::system_clock;
using orchestrator::ApiEdge;
using orchestrator::ApiGraphSummary;
using orchestrator::ApiSearchArgs;
using orchestrator::ApiSearchResults;
using orchestrator::ApiVertex;
using orchestrator::Orchestrator;
using grpc::Channel;
using grpc::ClientContext;
using grpc::ClientReader;
using grpc::ClientReaderWriter;
using grpc::ClientWriter;
using grpc::Status;
class OrchestratorApi final : public Orchestrator::Service {
public:
explicit OrchestratorApi(const std::string& name, std::shared_ptr<GraphOrchestrator> orchestrator)
: m_name(name), m_orchestrator(orchestrator) {}
Status AddVertex(ServerContext* context, ServerReader<ApiVertex>* reader, ApiGraphSummary* response) override {
ApiVertex vertex;
while (reader->Read(&vertex)) {
Logging::INFO("Add vertex with key: '" + vertex.key() + "' and value: '" + vertex.value() + "'", m_name);
}
response->set_vertex_count(0);
return Status::OK;
}
Status DeleteVertex(ServerContext* context, ServerReader<ApiVertex>* reader, ApiGraphSummary* response) override {
ApiVertex vertex;
while (reader->Read(&vertex)) {
Logging::INFO("Delete vertex with key: '" + vertex.key() + "'", m_name);
}
response->set_vertex_count(0);
return Status::OK;
}
Status DeleteEdge(ServerContext* context, ServerReader<ApiEdge>* reader, ApiGraphSummary* response) override {
ApiEdge edge;
while (reader->Read(&edge)) {
Logging::INFO("Delete edge: '" + edge.from() + "'---->'" + edge.to() + "'", m_name);
}
response->set_edge_count(0);
return Status::OK;
}
Status AddEdge(ServerContext* context, ServerReader<ApiEdge>* reader, ApiGraphSummary* response) override {
ApiEdge edge;
while (reader->Read(&edge)) {
Logging::INFO("Add edge: '" + edge.from() + "'--[" + edge.label() + "]-->'" + edge.to() + "'", m_name);
}
response->set_edge_count(0);
return Status::OK;
}
Status Search(ServerContext* context, const ApiSearchArgs* request, ApiSearchResults* response) override {
std::string query_key = request->query_key();
int level = request->level();
Logging::INFO("Search: '" + query_key + "'", m_name);
std::vector<std::string> vertices;
std::vector<std::string> edges;
Status status = m_orchestrator->Search(query_key, level, vertices, edges);
for (std::vector<std::string>::iterator it = vertices.begin(); it != vertices.end(); ++it) {
ApiVertex* vertex = response->add_vertices();
ApiVertex v;
v.set_key(*it);
v.set_value(*it);
*vertex = v;
}
for (std::vector<std::string>::iterator it = edges.begin(); it != edges.end(); ++it) {
ApiEdge* edge = response->add_edges();
ApiEdge e;
e.set_label(*it);
*edge = e;
}
return status;
}
private:
std::string m_name;
std::shared_ptr<GraphOrchestrator> m_orchestrator;
};
#endif
The ApiRunner utilizes this implementation to listen for incoming connections and RPC requests in a new thread.
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
31
32
/* api_runner.h */
#ifndef API_RUNNER_H
#define API_RUNNER_H
#include <grpc/grpc.h>
#include <memory>
#include <string>
#include <thread>
#include "graph_orchestrator.h"
#include "logging/log_signal.h"
#include "orchestrator_api.h"
class SignalChannel;
class ApiRunner {
private:
std::string m_name = "Api";
std::thread m_thread;
std::shared_ptr<SignalChannel> m_sig_channel;
std::shared_ptr<LogSignal> m_log_signal;
std::unique_ptr<grpc::Server> m_grpc_server;
std::shared_ptr<GraphOrchestrator> m_orchestrator;
public:
ApiRunner(std::shared_ptr<GraphOrchestrator> orchestrator, std::shared_ptr<SignalChannel> s,
std::shared_ptr<LogSignal> log_signal);
void RunServer();
~ApiRunner();
};
#endif
Here’s how the accompanying definition looks:
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
/* api_runner.cc */
#include "api_runner.h"
#include "logging/logging.h"
#include "orchestrator_api.h"
ApiRunner::ApiRunner(std::shared_ptr<GraphOrchestrator> orchestrator, std::shared_ptr<SignalChannel> s,
std::shared_ptr<LogSignal> log_signal)
: m_orchestrator(orchestrator), m_sig_channel(s), m_log_signal(log_signal), m_thread(&ApiRunner::RunServer, this) {}
void ApiRunner::RunServer() {
std::string server_address("0.0.0.0:" + std::to_string(50050));
OrchestratorApi service("localhost:" + std::to_string(50050), m_orchestrator);
ServerBuilder builder;
builder.AddListeningPort(server_address, grpc::InsecureServerCredentials());
builder.RegisterService(&service);
m_grpc_server = std::move(builder.BuildAndStart());
Logging::INFO("API running on '" + server_address + "'", m_name);
m_grpc_server->Wait();
}
ApiRunner::~ApiRunner() {
m_grpc_server->Shutdown();
m_thread.join();
}
Next, we require our orchestrator to establish communication with our workers. This entails utilizing the second API specified in the graph.proto protobuf file, which is utilized for intra-cluster communication tasks such as ping, adding new vertices and edges, etc. We already have a generated gRPC stub, graph::Graph::Stub, which we will now encapsulate within a GraphClient class for use by our orchestrator.
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
31
32
33
34
35
36
37
38
39
40
41
42
43
44
45
46
47
48
/* graph_client.h */
#ifndef GRAPH_CLIENT_H
#define GRAPH_CLIENT_H
#include <memory>
#include "../graph/in_memory_graph.h"
#include "../grpc/graph.grpc.pb.h"
using graph::Edge;
using graph::SearchArgs;
using graph::SearchResults;
using graph::Vertex;
using grpc::Status;
class GraphClient {
public:
GraphClient(std::shared_ptr<Channel> channel);
void AddVertices(const InMemoryGraph<std::string, std::string>::InMemoryVertex& v) const;
void DeleteVertex(const std::string& key) const;
void AddEdges(const InMemoryGraph<std::string, std::string>::InMemoryVertex& v,
const InMemoryGraph<std::string, std::string>::InMemoryEdge& e, const std::string& lookup_from) const;
void DeleteEdge(const std::string& from, const std::string& to) const;
Status Search(const std::string& key, const int max_level, SearchResults& result) const;
void AddHost(const std::string& key, const std::string& address) const;
bool Ping() const;
private:
Vertex MakeVertex(std::string key, std::string value) const;
SearchArgs MakeSearchArgs(std::string key, const int max_level) const;
Edge MakeEdge(const std::string& from, const std::string& to, const std::string& label,
const std::string& lookup_from, const std::string& lookup_to) const;
private:
std::unique_ptr<graph::Graph::Stub> stub_;
std::string m_name = "GraphClient";
};
#endif
Below is the definition of our GraphClient methods:
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
31
32
33
34
35
36
37
38
39
40
41
42
43
44
45
46
47
48
49
50
51
52
53
54
55
56
57
58
59
60
61
62
63
64
65
66
67
68
69
70
71
72
73
74
75
76
77
78
79
80
81
82
83
84
85
86
87
88
89
90
91
92
93
94
95
96
97
98
99
100
101
102
103
104
105
106
107
108
109
110
111
112
113
114
115
116
117
118
119
120
121
122
123
124
125
126
127
128
129
130
131
132
133
134
135
136
137
138
139
140
141
142
143
144
145
146
147
148
149
150
151
152
153
154
155
156
157
158
159
160
161
162
163
164
165
166
167
168
169
170
171
172
173
174
175
176
177
178
179
180
181
182
183
184
185
186
187
188
189
190
191
/* graph_client.cc */
#include "graph_client.h"
#include <grpc/grpc.h>
#include <grpcpp/channel.h>
#include <grpcpp/client_context.h>
#include <grpcpp/create_channel.h>
#include <grpcpp/security/credentials.h>
#include <iostream>
#include <memory>
#include <sstream>
#include <string>
#include <vector>
#include "../grpc/graph.grpc.pb.h"
#include "../logging/logging.h"
using grpc::Channel;
using grpc::ClientContext;
using grpc::ClientWriter;
using grpc::Status;
using graph::Graph;
using graph::GraphSummary;
using graph::Host;
using graph::PingRequest;
using graph::PingResponse;
using graph::SearchResults;
GraphClient::GraphClient(std::shared_ptr<Channel> channel) : stub_(Graph::NewStub(channel)) {}
void GraphClient::AddVertices(const InMemoryGraph<std::string, std::string>::InMemoryVertex& v) const {
ClientContext context;
GraphSummary stats;
std::unique_ptr<ClientWriter<Vertex>> writer(stub_->AddVertex(&context, &stats));
if (!writer->Write(MakeVertex(v.key_, v.data_))) {
Logging::ERROR("AddVertex error on write", m_name);
}
writer->WritesDone();
Status status = writer->Finish();
if (status.ok()) {
Logging::INFO("AddVertices finished with " + std::to_string(stats.vertex_count()) + " vertices", m_name);
} else {
Logging::ERROR("AddVertex rpc failed", m_name);
}
}
void GraphClient::DeleteVertex(const std::string& key) const {
ClientContext context;
GraphSummary stats;
std::unique_ptr<ClientWriter<Vertex>> writer(stub_->DeleteVertex(&context, &stats));
if (!writer->Write(MakeVertex(key, ""))) {
Logging::ERROR("DeleteVertex error on write", m_name);
}
writer->WritesDone();
Status status = writer->Finish();
if (status.ok()) {
Logging::INFO("DeleteVertex finished with " + std::to_string(stats.vertex_count()) + " vertices", m_name);
} else {
Logging::ERROR("DeleteVertex rpc failed", m_name);
}
}
void GraphClient::AddEdges(const InMemoryGraph<std::string, std::string>::InMemoryVertex& v,
const InMemoryGraph<std::string, std::string>::InMemoryEdge& e,
const std::string& lookup_from) const {
ClientContext context;
GraphSummary stats;
std::unique_ptr<ClientWriter<Edge>> writer(stub_->AddEdge(&context, &stats));
if (!writer->Write(MakeEdge(v.key_, e.to_, e.data_, lookup_from, e.lookup_to_))) {
Logging::ERROR("AddEdges error on write", m_name);
}
writer->WritesDone();
Status status = writer->Finish();
if (status.ok()) {
Logging::INFO("AddEdge finished with " + std::to_string(stats.edge_count()) + " edges", m_name);
} else {
Logging::ERROR("AddEdge rpc failed", m_name);
}
}
void GraphClient::DeleteEdge(const std::string& from, const std::string& to) const {
ClientContext context;
GraphSummary stats;
std::unique_ptr<ClientWriter<Edge>> writer(stub_->DeleteEdge(&context, &stats));
if (!writer->Write(MakeEdge(from, to, "", "", ""))) {
Logging::ERROR("DeleteEdge error on write", m_name);
}
writer->WritesDone();
Status status = writer->Finish();
if (status.ok()) {
Logging::INFO("DeleteEdge finished with " + std::to_string(stats.edge_count()) + " edges", m_name);
} else {
Logging::ERROR("DeleteEdge rpc failed", m_name);
}
}
Status GraphClient::Search(const std::string& key, const int max_level, SearchResults& result) const {
ClientContext context;
SearchArgs args = MakeSearchArgs(key, max_level);
Status status = stub_->Search(&context, args, &result);
if (!status.ok()) {
Logging::ERROR("Search rpc failed", m_name);
} else {
std::stringstream s;
s << "Finished with " << result.vertices().size() << " vertices:[";
std::string sep;
for (auto& v : result.vertices()) {
s << sep << v.key();
sep.assign(", ");
}
s << "] and " << result.edges().size() << " edges: [";
sep.assign("");
for (auto& e : result.edges()) {
s << sep << e.label();
sep.assign(", ");
}
s << "]";
Logging::INFO(s.str(), m_name);
}
return status;
}
void GraphClient::AddHost(const std::string& key, const std::string& address) const {
ClientContext context;
Host host;
host.set_key(key);
host.set_address(address);
::google::protobuf::Empty result;
Status status = stub_->AddHost(&context, host, &result);
if (status.ok()) {
Logging::INFO("AddHost finished", m_name);
} else {
Logging::ERROR("AddHost rpc failed", m_name);
}
}
bool GraphClient::Ping() const {
ClientContext context;
PingRequest ping;
ping.set_data("hello");
PingResponse response;
Status status = stub_->Ping(&context, ping, &response);
if (status.ok()) {
// Logging::INFO("Ping ok response: '" + response.data() + "'", m_name);
return true;
} else {
// Logging::ERROR("Ping rpc failed", m_name);
return false;
}
}
Vertex GraphClient::MakeVertex(std::string key, std::string value) const {
graph::Vertex v;
v.set_key(key);
v.set_value(value);
return v;
}
SearchArgs GraphClient::MakeSearchArgs(std::string key, const int max_level) const {
graph::SearchArgs a;
a.set_start_key(key);
a.set_level(max_level);
return a;
}
Edge GraphClient::MakeEdge(const std::string& from, const std::string& to, const std::string& label,
const std::string& lookup_from, const std::string& lookup_to) const {
graph::Edge e;
e.set_from(from);
e.set_to(to);
e.set_label(label);
e.set_lookup_from(lookup_from);
e.set_lookup_to(lookup_to);
return e;
}
We are simply utilizing the gRPC stub here, which is straightforward and can be referenced in any gRPC documentation.
To conclude the orchestrator setup, we need to furnish a main() method serving as the entry point. This method will integrate various components such as the data source, the orchestrator itself, and the API runner. Finally, it will initiate the API and listen for connections.
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
31
32
33
34
35
36
37
38
39
40
41
42
43
44
45
46
47
48
49
50
51
52
53
54
55
56
57
58
59
60
61
62
63
64
65
66
67
68
69
70
71
72
73
/* main.cc */
// ...
int main(int argc, char** argv) {
// ...
/*************************************************************************
*
* ORCHESTRATOR
*
*************************************************************************/
Logging::INFO("Init orchestrator", name);
std::shared_ptr<LockFreeQueue<std::string>> graph_queue = std::make_shared<LockFreeQueue<std::string>>();
OrchestratorBuilder orchestrator_builder;
std::shared_ptr<GraphOrchestrator> orchestrator =
orchestrator_builder.WithName("Orchestrator").WithWorkers(workers_config).WithInputQueue(graph_queue).Build();
/*************************************************************************
*
* HEALTH CHECKER
*
*************************************************************************/
std::unique_ptr<HealthChecker> checker = std::make_unique<HealthChecker>("HealthChecker", orchestrator);
ThreadDispatcher graph_health_checker(std::move(checker), sig_channel, log_signal);
while (!orchestrator->Healthy()) {
Logging::INFO("Waiting for orchestrator to become healthy", name);
auto delay = std::chrono::milliseconds(2000);
std::this_thread::sleep_for(delay);
}
orchestrator->Init();
ThreadDispatcher graph_poller(orchestrator, sig_channel, log_signal);
/*************************************************************************
*
* API (USER FACING)
*
*************************************************************************/
Logging::INFO("Init API", name);
ApiRunner api_runner(orchestrator, sig_channel, log_signal);
/*************************************************************************
*
* KAFKA
*
*************************************************************************/
std::map<std::string, std::string> kafka_config = config.kafka();
std::unique_ptr<KafkaMessageStrategy> ptr = KafkaFactory::GetInstance("PrintType", "Printer");
dynamic_cast<KafkaPrintMessageStrategy*>(ptr.get())->m_output_queue = graph_queue;
std::shared_ptr<KafkaDataSource> kafka =
KafkaBuilder()
.WithName("Kafka")
.WithBootstrapServers(kafka_config["bootstrap.servers"])
.WithClientId(kafka_config["client.id"])
.WithGroupId("foo")
.WithDeliveryReportCallback(std::move(std::make_unique<KafkaDeliveryReportCb>()))
.WithTopics({"graph_data"})
.WithKafkaMessageStrategy(std::move(ptr))
.Build();
ThreadDispatcher kafka_poller(kafka, sig_channel, log_signal);
while (!sig_channel->m_shutdown_requested.load()) {
}
// ...
}
Regrettably, this post is already saturated with code, aimed at enhancing the reader’s understanding of gRPC and the distributed graph concept. Therefore, I won’t delve into the specifics surrounding the orchestrator builder or health checker, as their implementations are straightforward and akin to the code snippets already provided. I’ll now proceed with discussing the worker components of the cluster.
Worker Classes
The primary data structure and core component of each worker is the InMemoryGraph class. This serves as the actual graph within the cluster, where each worker stores its vertices and edges. Additionally, it facilitates basic graph algorithms such as Breadth First Search (BFS) to fulfill the requirements of any orchestrator.
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
31
32
33
34
35
36
37
38
39
40
41
42
43
44
45
46
47
48
49
50
51
52
53
54
55
56
57
58
59
60
61
62
63
64
65
66
67
68
69
70
71
72
73
74
75
76
77
78
79
80
81
82
83
84
85
86
87
88
89
90
91
92
93
94
95
96
97
98
99
100
101
102
103
104
105
106
107
108
109
110
111
112
113
114
115
116
117
118
119
120
121
122
123
124
125
126
127
128
129
130
131
132
133
134
135
136
137
138
139
140
141
142
143
144
145
146
147
148
149
150
151
152
153
154
155
156
157
158
159
160
161
162
163
164
165
166
167
168
169
170
171
172
173
174
175
176
177
178
179
180
181
182
183
184
185
186
187
188
189
190
191
192
193
194
195
196
197
198
199
200
201
202
203
204
205
206
207
208
209
210
211
212
213
214
215
216
217
218
219
220
221
222
223
224
225
226
227
228
229
230
231
232
233
234
235
236
237
238
239
240
241
242
243
244
245
246
247
248
249
250
251
252
253
254
255
256
257
258
259
260
261
262
263
264
265
266
267
268
269
270
271
272
273
274
275
276
277
278
279
280
281
282
283
284
285
286
287
288
/* in_memory_graph.h */
#ifndef IN_MEMORY_GRAPH_H_
#define IN_MEMORY_GRAPH_H_
#include <iostream>
#include <map>
#include <queue>
#include <set>
#include <vector>
#include "../grpc/graph.grpc.pb.h"
#include "../worker/worker_graph_client.h"
template <typename VERTEX_DATA, typename EDGE_DATA>
class InMemoryGraph {
public:
int test;
using VERTEX_KEY = std::string;
using EDGE_KEY = std::string;
struct InMemoryVertex {
VERTEX_KEY key_;
VERTEX_DATA data_;
InMemoryVertex(VERTEX_KEY key, const VERTEX_DATA& data) : key_(key), data_(data) {}
bool const operator==(const InMemoryVertex& o) { return key_ == o.key_; }
bool operator<(const InMemoryVertex& o) const { return key_ < o.key_; }
};
struct InMemoryEdge {
VERTEX_KEY to_;
EDGE_DATA data_;
std::string lookup_to_;
InMemoryEdge(VERTEX_KEY to, const EDGE_DATA& edge_data, std::string lookup_to)
: to_(to), data_(edge_data), lookup_to_(lookup_to) {}
bool operator<(const InMemoryEdge& o) const { return to_ < o.to_ || (to_ == o.to_ && data_ < o.data_); }
};
private:
std::map<VERTEX_KEY, InMemoryVertex> vertices_;
std::map<VERTEX_KEY, std::set<InMemoryEdge>> edges_;
std::string worker_id_;
std::map<std::string, std::unique_ptr<graph::Graph::Stub>> worker_clients_;
public:
InMemoryGraph(std::string id) : worker_id_(id) {}
int NumberOfVertices() const { return vertices_.size(); }
int NumberOfEdges() const {
int count = 0;
for (const auto& [key, value] : edges_) {
count += value.size();
}
return count;
}
int NumberOfEdges(VERTEX_KEY key) const {
auto pos = edges_.find(key);
assert(pos != edges_.end());
return pos->second.size();
}
bool HasVertex(VERTEX_KEY key) { return (vertices_.find(key) != vertices_.end()); }
void AddVertex(VERTEX_KEY key, const VERTEX_DATA& data) {
std::cout << "[AddVertex] Adding vertex: '" << key << "' with data: '" << data << "'" << std::endl;
std::cout << "[AddVertex] Available edges before add:" << std::endl;
print_edges();
if (this->HasVertex(key)) {
std::cerr << "[AddVertex] Vertex with key: '" << key << "' already exists" << std::endl;
return;
}
assert(vertices_.find(key) == vertices_.end());
vertices_.insert({key, InMemoryVertex(key, data)});
edges_.insert({key, std::set<InMemoryEdge>()});
std::cout << "[AddVertex] Available edges after add:" << std::endl;
print_edges();
}
void DeleteVertex(VERTEX_KEY key) {
std::cout << "[DeleteVertex] Deleting vertex: '" << key << "'" << std::endl;
std::cout << "[DeleteVertex] Available edges before delete:" << std::endl;
print_edges();
if (!this->HasVertex(key)) {
std::cerr << "[DeleteVertex] Vertex with key: '" << key << "' does not exist" << std::endl;
return;
}
assert(vertices_.find(key) != vertices_.end());
const auto it_v = vertices_.find(key);
vertices_.erase(it_v);
const auto it_e = edges_.find(key);
edges_.erase(it_e);
std::cout << "[DeleteVertex] Available edges after delete:" << std::endl;
print_edges();
}
void print_edges() {
for (const auto& [key, to_edges] : edges_) {
for (const auto& to_edge : to_edges) {
std::cout << "'" << key << "'--[" << to_edge.data_ << "]-->'" << to_edge.to_ << "' with lookup_to: '"
<< to_edge.lookup_to_ << "'" << std::endl;
}
}
}
void AddEdge(VERTEX_KEY from, VERTEX_KEY to, const EDGE_DATA& data, const std::string lookup_to) {
std::cout << "[AddEdge] Adding edge: '" << from << "'-'" << to << "' with data: '" << data
<< "' and lookup_to: '" << lookup_to << "'" << std::endl;
std::cout << "[AddEdge] Available edges before add:" << std::endl;
print_edges();
if (!this->HasVertex(from)) {
std::cerr << "[AddEdge] Vertex with key: '" << from << "' does not exist" << std::endl;
return;
}
assert(edges_.find(from) != edges_.end());
edges_[from].emplace(InMemoryEdge(to, data, lookup_to));
std::cout << "[AddEdge] Available edges after add:" << std::endl;
print_edges();
}
void DeleteEdge(VERTEX_KEY from, VERTEX_KEY to) {
std::cout << "[DeleteEdge] Attempting to delete edge: '" << from << "'-'" << to << "'" << std::endl;
std::cout << "[DeleteEdge] Available edges before delete:" << std::endl;
print_edges();
if (edges_.find(from) == edges_.end()) {
std::cerr << "[DeleteEdge] Edge: '" << from << "'-'" << to << "' not available" << std::endl;
return;
}
assert(edges_.find(from) != edges_.end());
std::set<InMemoryEdge> edges = edges_.find(from)->second;
typename std::set<InMemoryEdge>::iterator it_e;
for (it_e = edges.begin(); it_e != edges.end();) {
if (!to.compare(it_e->to_)) {
it_e = edges.erase(it_e);
} else {
++it_e;
}
}
std::cout << "[DeleteEdge] Available edges after delete:" << std::endl;
print_edges();
}
void AddUndirectedEdge(VERTEX_KEY from, VERTEX_KEY to, const EDGE_DATA& data, const std::string lookup_to,
const std::string lookup_from) {
AddEdge(from, to, data, lookup_to);
AddEdge(to, from, data, lookup_from);
}
bool IsLocal(const std::string& data_source) { return !worker_id_.compare(data_source); }
void Search(std::string key, int max_level, std::set<graph::Vertex>& result_nodes,
std::set<graph::Edge>& result_edges, std::set<std::string>& ids_so_far,
const std::map<std::string, WorkerGraphClient>& rpc_clients) {
if (!this->HasVertex(key)) {
std::cout << "Vertex with key '" << key << "' is not in this graph" << std::endl;
return;
}
struct BFSEntry {
VERTEX_KEY key_;
int level_;
std::string data_source_;
};
ids_so_far.insert(key);
std::queue<BFSEntry> q;
q.push({key, 0, worker_id_});
while (!q.empty()) {
const auto queue_entry = q.front();
q.pop();
const auto current_key = queue_entry.key_;
const auto current_level = queue_entry.level_;
const auto data_source = queue_entry.data_source_;
if (IsLocal(data_source)) {
graph::Vertex rpc_vertex;
rpc_vertex.set_key(current_key);
result_nodes.insert(rpc_vertex);
if (current_level < max_level) {
// Iterate over its adjacent vertices
for (typename InMemoryGraph<std::string, std::string>::AdjacencyIterator e =
this->begin(current_key);
e != this->end(current_key); ++e) {
const auto edge = e.Edge();
const auto& to_key = e.To();
const auto& label = e.Data();
const auto& lookup_to = e.LookupTo();
std::string edge_key;
if (to_key.compare(current_key) < 0) {
edge_key.assign(to_key + label + current_key);
} else {
edge_key.assign(current_key + label + to_key);
}
graph::Edge rpc_edge;
rpc_edge.set_key(edge_key);
rpc_edge.set_from(current_key);
rpc_edge.set_to(to_key);
rpc_edge.set_label(label);
rpc_edge.set_lookup_from(worker_id_);
rpc_edge.set_lookup_to(lookup_to);
result_edges.insert(rpc_edge);
if (ids_so_far.find(to_key) == ids_so_far.end()) {
ids_so_far.insert(to_key);
q.push({to_key, current_level + 1, lookup_to});
}
}
}
} else {
int new_max_level = max_level - current_level;
if (new_max_level >= 0) {
rpc_clients.at(data_source)
.Search(current_key, new_max_level, result_nodes, result_edges, ids_so_far);
}
}
}
}
class VertexIterator {
std::vector<InMemoryVertex> vertices_;
int j_; // current vertex
public:
VertexIterator(const InMemoryGraph& g, int j) : j_(j) {
std::transform(
g.vertices_.begin(), g.vertices_.end(), std::back_inserter(vertices_),
[](const typename std::map<VERTEX_KEY, InMemoryVertex>::value_type& pair) { return pair.second; });
}
VertexIterator& operator++() {
assert(j_ < vertices_.size());
++j_;
return *this;
}
InMemoryVertex& Vertex() { return vertices_[j_]; }
VERTEX_KEY Key() { return vertices_[j_].key_; }
const VERTEX_DATA& Data() { return vertices_[j_].data_; }
bool operator!=(const VertexIterator& rhs) { return j_ != rhs.j_; }
};
VertexIterator begin() const { return VertexIterator(*this, 0); }
VertexIterator end() const { return VertexIterator(*this, NumberOfVertices()); }
class AdjacencyIterator {
std::vector<InMemoryEdge> edges_;
int j_; // current edge
public:
AdjacencyIterator(const InMemoryGraph& g, VERTEX_KEY v, int j)
: edges_(std::vector<InMemoryEdge>(g.edges_.at(v).begin(), g.edges_.at(v).end())), j_(j) {}
AdjacencyIterator& operator++() {
assert(j_ < edges_.size());
++j_;
return *this;
}
InMemoryEdge& Edge() { return edges_[j_]; }
VERTEX_KEY To() { return edges_[j_].to_; }
const EDGE_DATA& Data() { return edges_[j_].data_; }
const std::string LookupTo() { return edges_[j_].lookup_to_; }
bool operator!=(const AdjacencyIterator& rhs) { return j_ != rhs.j_; }
};
AdjacencyIterator begin(VERTEX_KEY v) const { return AdjacencyIterator(*this, v, 0); }
AdjacencyIterator end(VERTEX_KEY v) const { return AdjacencyIterator(*this, v, NumberOfEdges(v)); }
};
#endif
Given that every worker necessitates communication with other workers within the cluster, each worker requires a client analogous to the GraphClient utilized by the orchestrator. This client, named WorkerGraphClient, also encapsulates a graph::Graph::Stub object for intra-cluster communication.
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
31
32
33
34
35
36
37
38
39
40
41
/* worker_graph_client.h */
#ifndef WORKER_GRAPH_CLIENT_H_
#define WORKER_GRAPH_CLIENT_H_
#include <grpc/grpc.h>
#include <grpcpp/channel.h>
#include <grpcpp/client_context.h>
#include <grpcpp/create_channel.h>
#include <grpcpp/security/credentials.h>
#include <memory>
#include "../graph/helper.h"
#include "../grpc/graph.grpc.pb.h"
using graph::Graph;
using graph::SearchArgs;
using graph::SearchResults;
using grpc::Channel;
using grpc::ClientContext;
using grpc::Status;
class WorkerGraphClient {
private:
SearchArgs MakeSearchArgs(std::string key, int level, const std::set<std::string>& ids_so_far) const;
void UpdateNodes(const SearchResults& result, std::set<graph::Vertex>& nodes) const;
void UpdateEdges(const SearchResults& result, std::set<graph::Edge>& edges) const;
void UpdateIdsSoFar(const SearchResults& result, std::set<std::string>& ids_so_far) const;
public:
WorkerGraphClient(std::shared_ptr<Channel> channel) : stub_(Graph::NewStub(channel)) {}
void Search(const std::string& key, const int level, std::set<graph::Vertex>& result_nodes,
std::set<graph::Edge>& result_edges, std::set<std::string>& ids_so_far) const;
private:
std::unique_ptr<graph::Graph::Stub> stub_;
};
#endif
Here’s the accompanying method definition for the WorkerGraphClient:
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
31
32
33
34
35
36
37
38
39
40
41
42
43
44
45
46
47
48
49
/* worker_graph_client.cc */
#include "worker_graph_client.h"
SearchArgs WorkerGraphClient::MakeSearchArgs(std::string key, int level,
const std::set<std::string>& ids_so_far) const {
graph::SearchArgs a;
a.set_start_key(key);
a.set_level(level);
for (const auto& i : ids_so_far) {
std::string* id = a.add_ids_so_far();
*id = i;
}
return a;
}
void WorkerGraphClient::UpdateNodes(const SearchResults& result, std::set<graph::Vertex>& nodes) const {
for (const auto& v : result.vertices()) {
nodes.insert(v);
}
}
void WorkerGraphClient::UpdateEdges(const SearchResults& result, std::set<graph::Edge>& edges) const {
for (const auto& e : result.edges()) {
edges.insert(e);
}
}
void WorkerGraphClient::UpdateIdsSoFar(const SearchResults& result, std::set<std::string>& ids_so_far) const {
for (const auto& v : result.ids_so_far()) {
ids_so_far.insert(v);
}
}
void WorkerGraphClient::Search(const std::string& key, const int level, std::set<graph::Vertex>& result_nodes,
std::set<graph::Edge>& result_edges, std::set<std::string>& ids_so_far) const {
ClientContext context;
SearchResults result;
SearchArgs args = MakeSearchArgs(key, level, ids_so_far);
Status status = stub_->Search(&context, args, &result);
if (!status.ok()) {
std::cerr << "Search rpc failed." << std::endl;
} else {
UpdateNodes(result, result_nodes);
UpdateEdges(result, result_edges);
UpdateIdsSoFar(result, ids_so_far);
}
}
Lastly, we need to initialize our workers. Similar to the ApiRunner for the orchestrator mentioned earlier, we need to listen for incoming connections and handle RPC calls. This responsibility falls on the GraphImpl class, which implements the Graph::Service (as opposed to Orchestrator::Service). It acts as the internal-facing API, responsible for accepting and processing new requests from the orchestrator and other workers. It also incorporates a main() method responsible for parsing any command-line arguments and initiating the worker.
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
31
32
33
34
35
36
37
38
39
40
41
42
43
44
45
46
47
48
49
50
51
52
53
54
55
56
57
58
59
60
61
62
63
64
65
66
67
68
69
70
71
72
73
74
75
76
77
78
79
80
81
82
83
84
85
86
87
88
89
90
91
92
93
94
95
96
97
98
99
100
101
102
103
104
105
106
107
108
109
110
111
112
113
114
115
116
117
118
119
120
121
122
123
124
125
126
127
128
129
130
131
132
133
134
135
136
137
138
139
140
141
142
143
144
145
146
147
148
149
150
151
152
153
154
155
156
157
158
159
160
161
162
163
164
165
166
167
168
169
170
171
172
173
174
/* graph_worker.cc */
#include <grpc/grpc.h>
#include <grpcpp/create_channel.h>
#include <grpcpp/security/server_credentials.h>
#include <grpcpp/server.h>
#include <grpcpp/server_builder.h>
#include <grpcpp/server_context.h>
#include <algorithm>
#include <chrono>
#include <cmath>
#include <iostream>
#include <memory>
#include <string>
#include "../config/config_parser.h"
#include "../graph/helper.h"
#include "../graph/in_memory_graph.h"
#include "../grpc/graph.grpc.pb.h"
#include "worker_graph_client.h"
using grpc::Server;
using grpc::ServerBuilder;
using grpc::ServerContext;
using grpc::ServerReader;
using grpc::ServerReaderWriter;
using grpc::ServerWriter;
using grpc::Status;
using std::chrono::system_clock;
using graph::Edge;
using graph::Graph;
using graph::GraphSummary;
using graph::Host;
using graph::PingRequest;
using graph::PingResponse;
using graph::SearchArgs;
using graph::SearchResults;
using graph::Vertex;
using grpc::Channel;
using grpc::ClientContext;
using grpc::ClientReader;
using grpc::ClientReaderWriter;
using grpc::ClientWriter;
using grpc::Status;
class GraphImpl final : public Graph::Service {
public:
using InMemoryGraphType = InMemoryGraph<std::string, std::string>;
explicit GraphImpl(const std::string& id) : graph_(InMemoryGraph<std::string, std::string>(id)) {}
Status AddHost(ServerContext* context, const Host* request, ::google::protobuf::Empty* response) override {
rpc_clients_.insert({request->key(), WorkerGraphClient(grpc::CreateChannel(
request->address(), grpc::InsecureChannelCredentials()))});
return Status::OK;
}
Status AddVertex(ServerContext* context, ServerReader<Vertex>* reader, GraphSummary* response) override {
Vertex vertex;
while (reader->Read(&vertex)) {
graph_.AddVertex(vertex.key(), vertex.value());
}
response->set_vertex_count(graph_.NumberOfVertices());
return Status::OK;
}
Status DeleteVertex(ServerContext* context, ServerReader<Vertex>* reader, GraphSummary* response) override {
Vertex vertex;
while (reader->Read(&vertex)) {
graph_.DeleteVertex(vertex.key());
}
response->set_vertex_count(graph_.NumberOfVertices());
return Status::OK;
}
Status DeleteEdge(ServerContext* context, ServerReader<Edge>* reader, GraphSummary* response) override {
Edge edge;
while (reader->Read(&edge)) {
graph_.DeleteEdge(edge.from(), edge.to());
}
response->set_edge_count(graph_.NumberOfEdges());
return Status::OK;
}
Status AddEdge(ServerContext* context, ServerReader<Edge>* reader, GraphSummary* response) override {
Edge edge;
while (reader->Read(&edge)) {
graph_.AddEdge(edge.from(), edge.to(), edge.label(), edge.lookup_to());
}
response->set_edge_count(graph_.NumberOfEdges());
return Status::OK;
}
Status Search(ServerContext* context, const SearchArgs* request, SearchResults* response) override {
std::set<graph::Vertex> result_nodes;
std::set<graph::Edge> result_edges;
std::set<std::string> ids_so_far;
for (const auto& v : request->vertices()) {
result_nodes.insert(v);
}
for (const auto& e : request->edges()) {
result_edges.insert(e);
}
for (const auto& v : request->ids_so_far()) {
ids_so_far.insert(v);
}
graph_.Search(request->start_key(), request->level(), result_nodes, result_edges, ids_so_far, rpc_clients_);
// Collect the final results from the BFS Search
for (const auto& v : result_nodes) {
graph::Vertex* vertex = response->add_vertices();
*vertex = v;
}
for (const auto& e : result_edges) {
Edge* edge = response->add_edges();
*edge = e;
}
return Status::OK;
}
Status Ping(ServerContext* context, const PingRequest* request, PingResponse* response) override {
response->set_data("I'm alive!");
return Status::OK;
}
private:
InMemoryGraphType graph_;
std::map<std::string, WorkerGraphClient> rpc_clients_;
};
void RunServer(const int port) {
std::string server_address("0.0.0.0:" + std::to_string(port));
GraphImpl service("localhost:" + std::to_string(port));
ServerBuilder builder;
builder.AddListeningPort(server_address, grpc::InsecureServerCredentials());
builder.RegisterService(&service);
std::unique_ptr<Server> server(builder.BuildAndStart());
std::cout << "[Worker] Listening on " << server_address << std::endl;
server->Wait();
}
int main(int argc, char* argv[]) {
// ./src/build/graph_worker -c configs/worker_50051.yaml
std::string db_path;
std::string config_file;
/*************************************************************************
*
* COMMANDLINE ARGUMENTS
*
*************************************************************************/
graph::ParseArgs(argc, argv, config_file);
/*************************************************************************
*
* CONFIGURATION
*
*************************************************************************/
ConfigParser& config = ConfigParser::instance(config_file);
std::map<std::string, std::string> server_config = config.Server();
int listen_port = atoi(server_config.at("port").c_str());
RunServer(listen_port);
return 0;
}
Final Thoughts
If you’ve made it this far, congratulations and thank you for your persistence. I wouldn’t be surprised if you have a few questions about the code. As mentioned numerous times, to get a complete understanding of the setup, please refer to the GitHub repository. It will greatly aid in piecing together the various components.
It’s important to note that this code isn’t production-ready, as there are many missing features that one would expect from a graph database, as well as better approaches that could be implemented. However, as I’ve transitioned to a different project recently, I decided to publish what I’ve developed so far, as there’s still a lot to learn from it in its current state, even if its just a prototype.
Feel free to provide feedback, and be sure to explore my other posts. Thank you again for your attention and engagement.